





重新学习 Docker 整理,docker 版本 18.06
Docker 安装注意事项
安装脚本:
yum install -y yum-utils device-mapper-persistent-data lvm2 |
若要使普通用户也能有直接操作 Docker 命令的权限(不需要 sudo),可将该用户添加到 docker 组内。先要确保/var/run/docker.sock所属组为 docker。
开启包转发以及透明防火墙
iptables netfilter通过与linux bridge联动,netfilter会在bridge层执行钩子函数,实现透明防火墙功能。
开启br_netfilter的方法:
在/proc/sys/net/bridge/中有三个开关,对于IP table只要关注ip6tables和iptables即可。
bridge-nf-call-arptables |
先确保br_netfilter模块已经加载
# lsmod |grep br_netfilter |
如果执行以上命令查看没有对应模块的话,则需开启模块
modprobe br_netfilter |
然后在/etc/sysctl.conf中添加,或者在/etc/sysctl.d/中创建文件添加
net.bridge.bridge-nf-call-ip6tables = 1 |
并执行
sysctl -p |
系统重启后模块会失效,因此需要添加开机自动加载模块的脚本
创建文件/etc/rc.sysinit,写入以下内容
|
创建文件/etc/sysconfig/modules/br_netfilter.modules,并写入
modprobe br_netfilter |
添加权限
chmod 755 /etc/sysconfig/modules/br_netfilter.modules |
添加包转发,开关为/proc/sys/net/ipv4/ip_forward。将linux系统作为路由或vpn服务就必须开启IP转发功能,当linux主机有多个网卡时一个网卡收到的信息能否传递给其他网卡,若设为1,则可进行数据包转发,实现vxlan等功能,若不开启则会导致docker应用无法访问。
同理,在/etc/sysctl.conf中添加,或者在/etc/sysctl.d/中创建文件添加
net.ipv4.ip_forward = 1 |
并执行
sysctl -p |
Docker 基础命令集
环境信息:
docker info:显示 docker 配置信息docker version:显示 docker 版本号
容器生命周期管理:
docker create:创建容器docker exec:对运行的容器执行一条命令docker kill:杀死容器docker pause:停止指定容器的所有进程docker restart:重启容器docker rm:删除容器docker run:创建并运行容器。run 就是 create 和 start 的组合docker start:启动一个或多个停止的容器docker stop:停止一个或多个容器docker unpause:恢复指定容器的所有进程继续运行
镜像仓库管理:
docker login:登录到 Docker 仓库docker logout:登出 Docker 仓库docker pull:拉取镜像docker push:上传镜像docker search:搜索镜像
镜像管理:
docker build:用 Dockerfile 构建一个镜像docker images:查看镜像docker import:docker load:docker rmi:docker save:docker tag:docker commit:因为容器的变化而构建一个新的镜像
容器运维管理:
docker attach:连接进入一个容器docker export:docker inspect:docker port:docker ps:列出容器docker rename:重命名一个容器docker stats:docker top:docker wait:docker cp:docker diff:docker update:
容器资源管理:
docker volume:管理数据卷docker network:管理网络
系统日志信息:
docker events:获取一个容器的实时信息docker history:显示一个镜像的构建历史信息docker logs:获取一个容器的日志
常用命令调用过程:
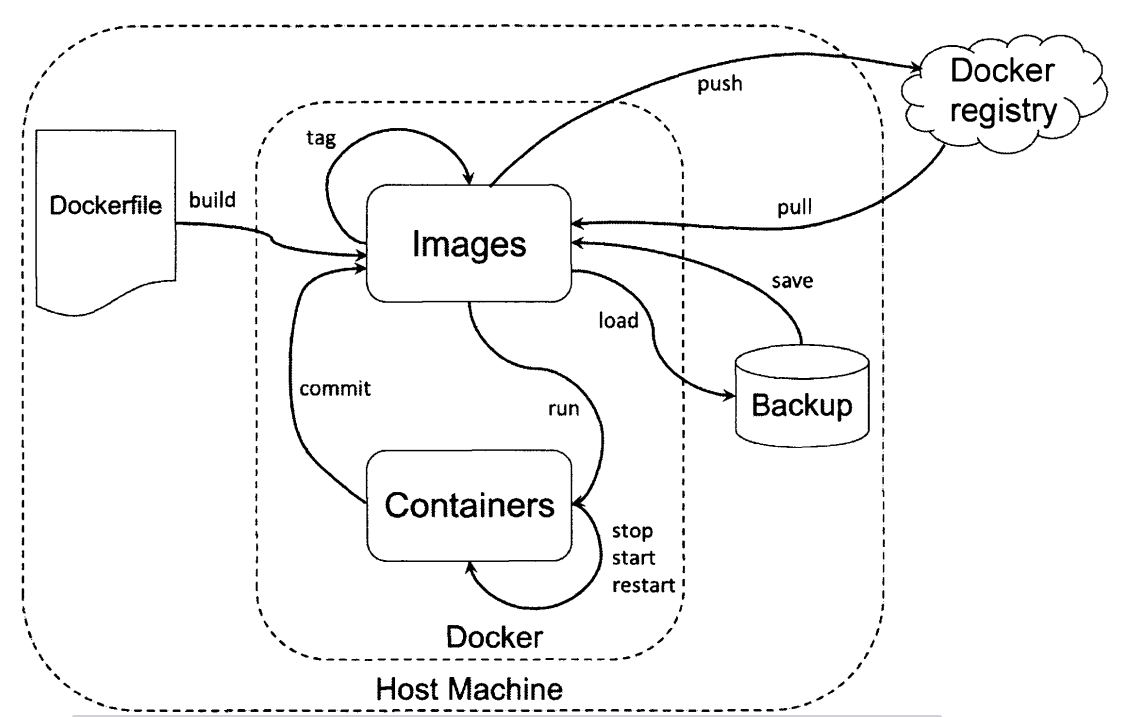
Docker 核心原理
namespace
Linux 内核虚拟化容器技术(LXC Kernel Namespace),将某个特定的全局系统资源通过抽象方法使得 namespace 中的进程看起来拥有自己的隔离的全局系统资源实例。LXC 提供以下六种隔离的系统调用。
| namespace | 隔离的资源 |
|---|---|
| UTS | 主机名和域名 |
| IPC | 进程间通信资源(信号量、消息队列、共享内存) |
| PID | 进程编号 |
| Network | 网络相关资源(网络设备、网络栈、端口等) |
| Mount | 挂载点(文件系统) |
| User | 用户与用户组 |
cgroups
cgroups 全称control groups,是 Linux 内核的一种机制,可根据需求把一系列系统任务及子任务整合到按资源划分等级的不同组内,从而为系统资源管理提供一个统一的框架。即 cgroups 可以限制、记录任务组所使用的物理资源。
本质上,cgroups 是内核附加在程序上的一系列钩子 hook,通过程序运行时对资源的调度,触发相应的 hook 函数,以达到资源追踪和限制的目的。
cgroups 特点:
- cgroups 的 API 以一个伪文件系统实现,用户态的程序可以通过文件操作实现 cgroups 的组织管理
- cgroups 的组织操作单元的细粒度可达到线程级别,用户可创建销毁 cgroups,实现资源再分配和管理
- 所有资源管理功能都以子系统方式实现,接口统一
- 子任务创建之初与父任务处于同一个 cgroups 控制组
cgroups 功能:
- 资源限制:对任务使用的资源总额进行限制。一旦超出配额就发出OOM(out of memory)的警告
- 优先级分配:通过分配的CPU 时间片数量及磁盘 IO 带宽大小,实际上就相当于控制了任务运行的优先级
- 资源统计:统计系统的资源使用量,适合于计费
- 任务控制:可对任务执行挂起、恢复等操作
cgroups 术语:
- task:任务,表示系统的一个进程或线程
- cgroup:控制组,cgroups 中资源控制都是以 cgroup 为单位,表示按某种资源控制标准划分而成的任务组,包含一个或多个子系统。任务可在 cgroup 间迁移
- subsystem:子系统,是一个资源调度控制器
- hierarchy:层级,由一系列 cgroup 以一个树状结构排列,每个层级通过绑定对应的子系统进行资源控制,并且子节点能继承父节点挂载的子系统。
层级规则
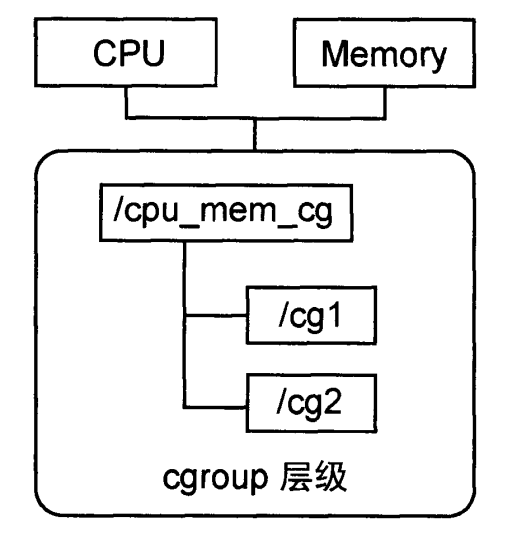
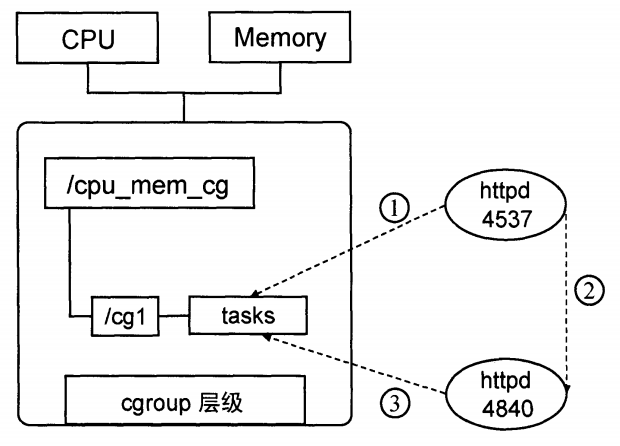
规则 1:同一个层级可附加一个或多个子系统。事例如图,CPU 和 Memory 子系统附加到一个层级上
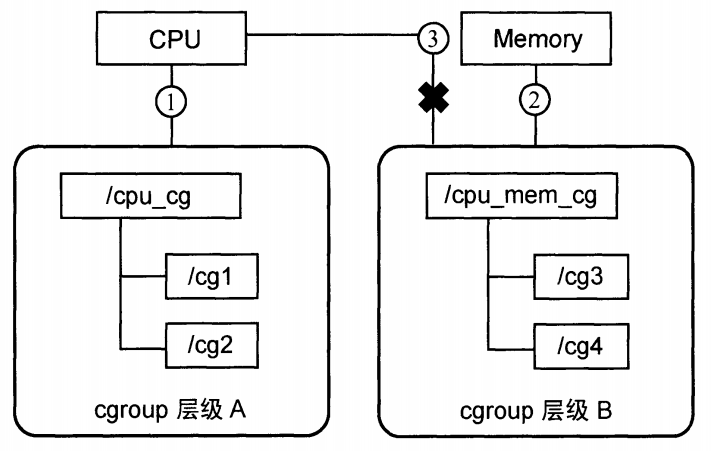
规则 2:一个子系统可附加到多个层级上(仅当目标层级只有唯一一个子系统时),一个已经附加在某个层级上的子系统不能附加到其他含有别的子系统的层级上。
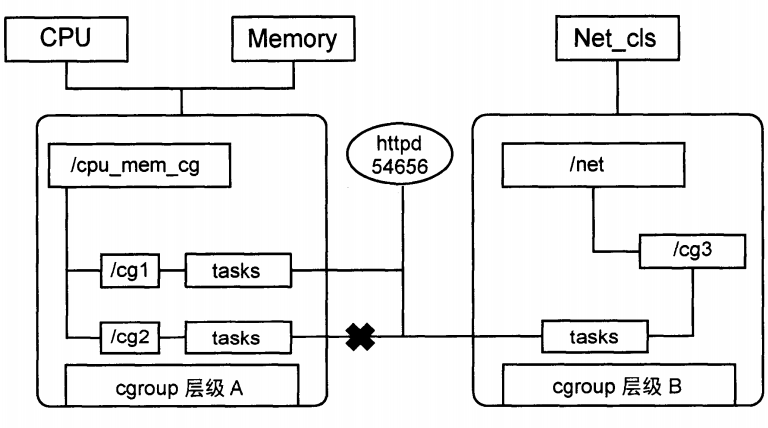
规则 3:每新建一个层级时,该系统上所有任务默认加入这个新建层级的初始化 cgroup,称为 root cgroup。一个任务不能存在于同一个层级的不同 cgroup,但可以存在于不同层级的多个 cgroup 中。若将一个任务添加到同一层级的另一个 cgroup,则会自动将其从第一个 cgroup 中移除。
规则 4:任务在 fork/clone 自身时创建的子任务默认与原任务在同一个 cgroup,但完成后,父子任务间在 cgroup 方面互不影响。
子系统
子系统是 cgroups 的资源控制系统,每种子系统独立控制一种资源。Docker 有以下子系统:
- blkio:限制块设备输入输出
- cpu:控制对 CPU 的使用
- cpuacct:对 CPU 资源使用情况的报告
- cpuset:分配独立的 CPU 和内存
- devices:开启/关闭任务对设备的访问
- freezer:挂起/恢复任务
- memory:限定任务的内存使用量,并生成内存资源使用报告
- perf_event:可进行统一的性能测试
- net_cls:控制网络流量,识别数据包
Linux 中 cgroup 表现为一个文件系统,需要 mount 才能使用。
# mount -t cgroup |
子系统文件都存放在/sys/fs/cgroup目录中。Docker daemon 会在每个子系统的控制组目录中创建一个 docker 控制组,并在其中为每个容器创建一个以容器 ID(长 ID)为名称的容器控制组,该容器中所有任务的 TID(进程或线程的 ID)都会写入该控制组的 tasks 文件。
# tree /sys/fs/cgroup/cpu/docker/ |
cgroups 实现原理
cgroups 如何判断资源超限并做出措施
对于不同系统资源,cgroups 提供了统一的接口对资源进行控制和统计。会有描述子系统资源状态的结构体记录所属 cgroup,当进程申请更多资源时,会触发 cgroup 用量检测,若超出限额,则拒绝,否则就给予相应资源并记录在统计信息中,不仅要考虑资源的分配和回收,还要考虑不同类型的资源等。
在超出限额后,会根据信号(如果设置的话)(如内存的 OOM 信号)决定进程是否挂起或继续执行。
cgroup 与任务之间的关联关系
cgroup 与任务间是多对多关系,并不直接关联,而是通过一个中间结构将双向的关联信息记录。每个任务结构体能通过指针查询对应 group 的情况,也能查询各个子系统的情况,结构体把子系统状态指针包含进来,并由内核通过 container_of 宏定义获取对应结构体,关联到任务,实现资源限制。
使用注意
Docker 需要挂载 cgroup 文件系统新建一个层级结构,挂载时指定要绑定的系统。除 cgroup 文件系统外,内核没有为 cgroups 的访问和操作添加任何系统调用。
无法将一个新的子系统绑定到一个已激活的层级,或从一个层级解除某个子系统的绑定。
只有递归卸载层级中的所有 cgroup,该层级才会被真正删除,否则即使上层的层级删除了,后代的 cgroup 中的配置也会依然生效。
在容器目录下,会有以下固定文件,描述 cgroup 相应信息。
- tasks:在该 cgroup 中任务的进程或线程 ID(无序),意味着把这个任务加入这个 cgroup。
- cgroup.procs:记录所有在 cgroup 的 TGID(线程组 ID,是线程组中第一个进程的 ID),意味着将与其相关的线程都加到这个 cgroup 中。
- notify_on_release:是否在 cgroup 中最后一个任务退出时通知运行 release agent,默认为 0,不运行。若为 1 则表示运行
Docker 架构
采用 C/S 架构,用户通过 Docker client 与 Docker daemon 建立通信。
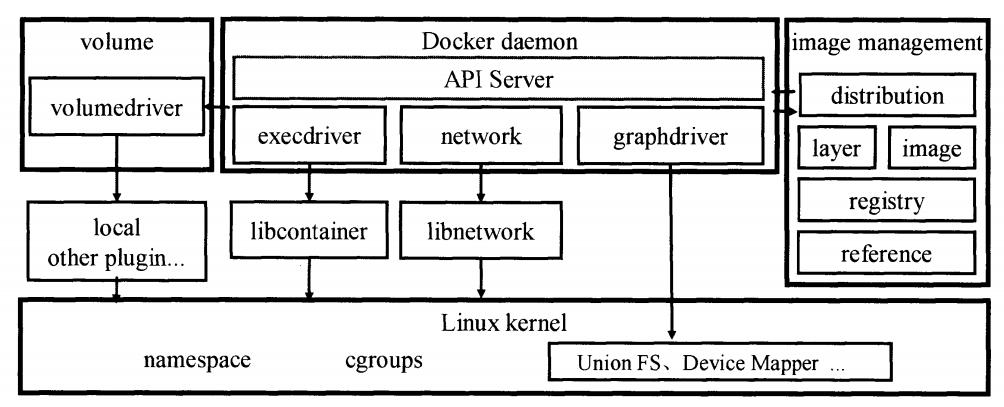
- docker daemon 是 docker 的核心后台进程,响应 client 的请求,然后调度给容器操作。
- docker client 向 daemon 发送请求,可以是命令
docker,也可以是使用了 docker API 的应用。 - image management:docker 通过 distribution、registry、layer、image、reference 等模块实现 docker 镜像管理。
- distribution:与 docker registry 交互,上传下载镜像及存储 registry 的元数据
- registry:与 docker registry 有关的身份验证、镜像查找、镜像验证等操作
- image:与镜像元数据相关的存储、查找、镜像层索引、镜像 tar 包导入导出的交互操作
- reference:存储本地所有镜像的 repository 和 tag 名,维护与镜像 ID 间的映射关系
- layer:与镜像层、容器层元数据有关的增删改查,将镜像层操作映射到实际存储镜像层文件系统的 graphdriver 模块
- docker daemon 包含的三个主要模块:execdriver(容器执行驱动)、volumedriver(volume 存储驱动)、graphdriver(镜像存储驱动)
- execdriver:是对 namespaces、cgroups、selinux 等系统操作的二次封装,比 LXC 功能更全面。默认实现是官方的 libcontainer 库
- volumedriver:是 volume 存储操作的执行者,负责 volume 增删改查。默认实现是 local,默认将文件存放在 docker 根目录下 volume 目录
- graphdriver:是所有与容器镜像相关操作的执行者,会在 docker 工作目录下维护一组与镜像层对应的目录,存放镜像层关系和元数据。主要支持的 graphdriver:aufs、btrfs、zfs、devicemapper、overlay、vfs
- libnetwork:抽象出了容器网络模型(Container Network Model),提供统一接口。抽象除了 sandbox、endpoint、network 对象,由具体网络驱动操作对象,通过网络控制器的统一接口供调用者管理网络。主要实现:创建网络、创建 network namespace、虚拟网卡和所有网络相关配置等
镜像管理
Docker 镜像的文件内容以及一些运行 Docker 容器的配置文件组成了 Docker 容器的静态文件系统运行环境——rootfs。
rootfs 是 Docker 容器在启动时内部进程可见的文件系统,即 Docker 容器的根目录。docker daemon 为 Docker 容器挂载 rootfs 时,先将 rootfs 设为只读(read-only),在挂载完毕后,利用联合挂载(union mount)在 rootfs 上再挂载一个读写层,使得读写层位于 Docker 容器文件系统的最顶层,下面是多个只读层。
Docker 镜像的特点:
- 分层
- 写时复制(copy-on-write):在多个容器间共享镜像,只有 Docker 容器运行时文件系统变化时,才会把变化的文件写到可读写层。写时复制减少了镜像对磁盘空间的占用和容器启动时间。
- 内容寻址存储(content-addressable storage):该机制根据文件内容索引镜像和镜像层。会对镜像层生成内容哈希值,作为镜像层唯一标识。提高了镜像安全性,并能检测数据完整性。
- 联合挂载:可以在一个挂载点同时挂载多个文件系统,将挂载点的原目录与被挂载内容进行整合。实现联合挂载的文件系统称为联合文件系统(union filesystem)。
Docker镜像构建
两种方式:
docker commit: 通过容器构建docker build [option] [build context]: 通过dockerfile构建
默认会从所在目录找Dockerfile
-t: 指定镜像名
-f: 指定Dockerfile路径
--force-rm=true: 强制删除所有中间镜像
--no-cache=true: 不使用缓存构建
--pull=true: 检查是否有该镜像的最新版本,并拉取最新版本注:
.的作用并不是指定Dockerfile的路径。
docker在运行时分为docker引擎和docker客户端cli,使用时就是通过cli命令行与docker引擎交互。docker build就是在docker引擎中构建,而非本机环境。
当构建时,由用户指定构建的上下文路径,而docker build会将该路径下所有文件都打包传给docker引擎,引擎内将包打开获得文件。若拷贝的文件超出了上下文的范围,docker引擎是找不到那些文件的。
. 就是在指定镜像构建过程中上下文环境的目录
dockerfile镜像构建过程
- docker将build context中的所有文件发给docker daemon。(所以千万不要将build context定为根目录等文件量庞大的目录,一定要新建目录以便管理)
- daemon 通过Dockerfile中的add、copy将目录中指定文件添加到镜像中。
Dockerfile文件参数
FROM <image>:<tag>: 基础镜像,必须是第一条(scratch 为从头开始构建,不依赖任何基础镜像)MAINTAINER <name>: 指定镜像作者信息RUN指定当前镜像中运行的命令两种模式:
RUN <command>shell模式RUN [""]exec模式EXPOSE <port>: 指定运行该镜像的容器使用的端口。虽然此处指定了端口号,但处于安全考虑,docker不会就直接使用,所以在创建容器时仍需要-p 指定端口CMD: 指定容器运行的默认命令,docker run指定shell的话,cmd就不生效["执行命令","参数1","参数2"]若定义了ENTRYPOINT,此时CMD作为ENTRYPOINT的参数["参数1","参数2"]
一个Dockerfile只能有一个CMD,多个就只有最后一个生效ENTRYPOINT: 类似cmd,但不会被docker run中指定的shell覆盖类似RUN,两种模式:
["执行命令","参数1","参数2"](exec模式)command(shell模式)
一个Dockerfile只能有一个ENTRYPOINT,多个就只有最后一个生效
可使用docker run --entrypoint覆盖
可与cmd进行组合,cmd指定命令,entrypoint指定命令默认参数
当定义ENTRYPOINT后,CMD只能作为参数传递ADD <src> <dest>: 将文件目录复制到dockerfile所在镜像中,且包含类似tar解压功能。如果复制tar文件(包括gzip,bzip,xz压缩文件),是必定会被解压的,也就是无法复制原本的tar文件。
若单纯复制文件,推荐使用copyCOPY <src> <dest>: 同上["src"....."dest"]使用于路径中有空格的情况VOLUME: 向容器添加卷WORKDIR: 设置容器工作目录(进入容器后的当前目录,若不存在docker会自动创建)
若设置多个WORKDIR ,路径需要注意,若不填绝对路径,工作路径会沿着设置顺序进入ENV <key> <value>: 环境变量USER: 设置指定用户启动服务(不指定就默认root)- user 2. uid 3. user:group 4. uid:gid 5.user:gid 6. uid:group
ONBUILD: 镜像触发器,当一个镜像被其他镜像作为基础镜像时执行,会在构建时插入指令。本次构建镜像是不会被触发的,只有以此构建的镜像作为基础镜像时才会被触发。LABEL <key>=<value>: 设置标签,键值都可自定义
资源限制
实际就是配置cgroup
- 容器内存: 包含两部分:物理内存与swap
-m指定内存大小--memory-swap指定内存和swap一共大小(默认为指定内存两倍)容器最多使用 200M 物理内存和 200M swap。 - 容器CPU。默认设置下,所有容器可以平等地使用 host CPU 资源并且没有限制
-c (--cpu-shares)设置cpu容器使用cpu权重,默认1024
例:一个docker run -c 1024,一个docker run -c 512那么第一个占有cpu就是第二个的2倍,即第一个占有cpu总量的2/3,第二个占1/3--cpuset-cpus 0-3|0,1,2指定cpu编号(根据虚拟机情况,从0开始编号,若连续可用-,若不连续可用, 分隔) - 容器磁盘。Block IO 指 磁盘读写。可以通过设置权重、限制bps和iops控制读写磁盘的带宽。目前 Block IO 限额只对 direct IO(不使用文件缓存)有效。
--blkio-weight改变block io优先级。默认500(修改类似cpu)
bps:每秒读写数据量 iops:每秒IO次数
加--device-read-bps|write-bps|read-iops|write-iops分别限制读|写某设备的bps|iops,后面加上设备名:速率
例:docker run -it --device-write-bps /dev/sdb:30MB centos
对于多核cpu的服务器,可使用--cpuset-cpus和--cpuset-mems控制容器运行限定在哪些cpu内核以及内存节点上。对具有NUMA拓扑的服务器尤其有用,可对需要高性能的容器进行性能最优的配置。
服务器架构一般分为:SMP、NUMA、MPP体系
- SMP(Symmetric Multi-Processor)对称多处理器结构。例:x86服务器,双路服务器,主板上有两个物理cpu
- NUMA(Non-Uniform Memory Access)非一致存储访问结构。例:IBM小型机
- MPP(Massive ParallelProcessing)海量并行处理结构。例:大型机Z14
CPU配额控制参数的混合使用
cpu-shares控制只发生在容器竞争同一个cpu的时间片时有效。如果通过cpuset-cpus指定容器A使用CPU 0,容器B使用CPU 1,在主机上只有这两个容器使用对应内核的情况,它们各自占用全部内核资源,cpu-shares没有明显效果。
只有当容器A和容器B上cpuset-cpus值都设置为同一个cpu上,并同时抢占cpu资源,才能看出cpu-shares的效果。
容器安全
参考资料
- 《Docker 开发指南》
- 《Docker 容器与容器云》
- Docker 官方文档 版本 18.03