





本篇文章将完整描述基于ELK的日志系统的设计与部署,以及所有涉及的知识点。
Elasticsearch
Elasticsearch 是基于 Lucene 的搜索框架,使用 Java 编写,它提供了一个分布式多用户能力的全文搜索引擎,基于 RESTful web 接口,上手容易,拓展节点方便,可用于存储和检索海量数据,接近实时搜索,海量数据量增加,搜索响应性能几乎不受影响。
Apache Lucene:目前存在的拥有最先进,高性能和全功能搜索引擎功能的库。但仅仅是一个库,Elasticsearch 则是提供了 Lucene 库的 RESTful API 接口,将所有的功能打包成一个单独的服务,做到”开箱即用“。
Elasticsearch 主要特点:
- 全文检索,结构化检索
- 数据统计、分析,接近实时处理
- 分布式搜索(可部署数百台服务器)
- 自动发现节点
- 副本机制
- 处理 PB 级别的结构化或者非结构化数据
- 保障可用性
- 搜索纠错,自动完成
- 与各种语言集成,与 Hadoop、Spark 等大数据分析平台集成
使用场景:日志搜索,数据聚合,数据监控,报表统计分析
使用 Elasticsearch 的大企业:维基百科、卫报、StackOverflow、Github、ebay
Elasticsearch集群安装
- 准备三台以上的单数台节点
- 因为 Lucene 和 Elasticsearch 都是 Java 写的,所以首先搭建 JDK 环境,每台上都安装jdk
- 下载 Elasticsearch,使用的版本7.5,使用rpm方式安装
下载地址:https://www.elastic.co/cn/downloads/past-releases#elasticsearch
- 先不启动,修改内核参数配置,在
/etc/sysctl.d/创建es.confvm.max_map_count = 262144 # 最大虚拟内存
fs.file-max=1000000
net.ipv4.tcp_max_tw_buckets = 6000
net.ipv4.tcp_sack = 1
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_rmem = 4096 87380 4194304
net.ipv4.tcp_wmem = 4096 16384 4194304
net.ipv4.tcp_max_syn_backlog = 16384
net.core.netdev_max_backlog = 32768
net.core.somaxconn = 32768
net.core.wmem_default = 8388608
net.core.wmem_max = 16777216
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_fin_timeout = 20
net.ipv4.tcp_synack_retries = 2
net.ipv4.tcp_syn_retries = 2
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_mem = 94500000 915000000 927000000
net.ipv4.tcp_max_orphans = 3276800
net.ipv4.ip_local_port_range = 1024 65000
net.nf_conntrack_max = 6553500
net.netfilter.nf_conntrack_max = 6553500
net.netfilter.nf_conntrack_tcp_timeout_close_wait = 60
net.netfilter.nf_conntrack_tcp_timeout_fin_wait = 120
net.netfilter.nf_conntrack_tcp_timeout_time_wait = 120
net.netfilter.nf_conntrack_tcp_timeout_established = 3600
net.core.rmem_default = 33554432
net.core.rmem_max = 33554432 - 设置ulimit限制,修改
/etc/security/limits.conf* soft nproc 1000000
* hard nproc 1000000
* soft nofile 1000000
* hard nofile 1000000 - 修改配置文件
/etc/elasticsearch/elasticsearch.yml,需要先创建数据目录和日志目录,每台的node.name也要去修改node.name: node-1
node.master: true
node.data: true
path.data: /data/es/data
path.logs: /data/es/logs
bootstrap.memory_lock: true
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
http.cors.enabled: true
http.cors.allow-origin: "*" - 然后启动es,
systemctl start elasticsearch,使es完成一些初始化数据操作。es都启动完成后,再停止掉es。 - 继续修改es配置
cluster.name: cluster1
cluster.initial_master_nodes: node-1
discovery.zen.ping.unicast.hosts: ["xx.xx.xx.xx","xx.xx.xx.xx", "xx.xx.xx.xx"]
discovery.zen.minimum_master_nodes: 2
xpack.security.enabled: false - 依次启动
Elasticsearch 配置文件
ES 核心配置文件config/elasticsearch.yml
cluster.name: my-application #集群名称,若相同,且是同一网段会自动加入 |
JVM 配置文件jvm.option,最好不要调。
-Xms1g #最小堆内存 |
Elasticsearch 概念
Elasticsearch 是 面向文档 的,意味着它存储整个对象或文档。且 Elasticsearch 不仅存储文档,而且索引每个文档的内容使之可以被检索。在 Elasticsearch 中,是对文档进行索引、检索、排序和过滤,而不是对行列数据。这就是 ES 能支持复杂的全文搜索的原因。
Elasticsearch 使用 JSON 作为文档的序列化格式。存储数据到 Elasticsearch 的行为叫做索引(动词,索引一个文档就是存储一个文档到索引),一个 Elasticsearch 集群可以包含多个索引 ,相应的每个索引可以包含多个类型 。这些不同的类型存储着多个文档 ,每个文档又有多个字段 。Elasticsearch 和 Lucene 使用倒排索引(也称反向索引)结构达到较高的检索速度。倒排索引就是关系型数据库通过增加一个索引到指定列上以提高搜索速度。
REST
Representational State Transfer 表述性状态传递,是一种软件架构风格,提供的是一组设计原则和约束条件,主要用于客户端与服务器交互的软件,使得软件更简洁、有层次,更利于实现缓存等机制。
REST 提供的与资源交互的方法:类似于 HTTP,但 REST 的方法仅仅面向资源,无法对 web 应用操作。
- GET:列出 URI 以及资源中详细信息
- PUT:将给定的一组资源替换当前资源
- POST:在指定资源中创建、追加一个新资源
- DELETE:删除资源
- HEAD:获取头信息
PUT /megacorp/employee/1 |
megacorp为索引名,employee为类型名,1为雇员 ID。Elasticsearch 仅需要找到雇员 ID 文件,就能知道该雇员的所有信息。
若要与关系型数据库对照,索引(indice 或 index)对应库,类型(type)对应表,文档(document)对应行,字段(field)对应列
Elasticsearch 通过将数据分片(shards)存储以解决数据量大时不能直接存储在一块硬盘中,且无法一次性搜索超大的数据量的情况。创建索引时,只需定义所需的分片数即可。每个分片本身都是一个功能齐全且独立的“索引”,可以托管在集群中的任何节点上。
每个 Elasticsearch 分片都是 Lucene 索引。每个 Lucene 可包含的最大文件数量为 Integer.MAX_VALUE - 128 个文件可以使用
/_cat/shards监视分片大小。
并通过创建分片的副本(replicas),当主分片不可用时,副本就充当主分片使用。Elasticsearch 为每个索引分配 5 个主分片和 1 个副本,若集群中有两个节点,该索引的分片数会翻倍,即 10 个分片。
集群原理
一个运行的 Elasticsearch 实例为一个节点,集群是由一个或多个拥有相同cluster.name的节点构成的,当有节点加入集群中或者从集群中移除节点时,集群将会重新平均分布所有的数据。
cluster.name默认为elasticsearch
主节点:负责管理集群范围内的所有变更(增删索引和节点等),任何节点都可以成为主节点。主节点并不需要涉及到文档级别的变更和搜索等操作,因此流量的增加它也不会成为瓶颈。
每个节点都知道任意文档所处的位置,并且能够将请求直接转发到存储客户所需文档的节点。
集群健康
可通过curl localhost:9200/_cluster/health或使用telnet 127.0.0.1 9200并输入GET /_cluster/health HTTP/1.1获取集群的健康状况,或通过curl 127.0.0.1 9200/_cat/health?v查看。
{ |
其中健康状况就是字段status,有三个可能值:
green:所有的主分片和副本分片都正常运行yellow:所有的主分片都正常运行,但不是所有的副本分片都正常运行red:有主分片没能正常运行,数据可能丢失,需要紧急修复
水平扩容
读操作、搜索和返回数据都可以同时被主分片或副本分片所处理,所以拥有越多的副本分片时,也将拥有越高的吞吐量。在运行中的集群上是可以动态调整副本分片数目的 ,可以按需伸缩集群。
curl -H "Content-Type: application/json" -X PUT localhost:9200/blogs/_settings -d ' |
如果只是在相同节点数目的集群上增加更多的副本分片并不能提高性能,因为每个分片从节点上获得的资源会变少,需要增加更多的硬件资源来提升吞吐量,但是更多的副本分片数提高了数据冗余量。
添加索引
可通过curl添加索引
curl -H "Content-Type: application/json" -X PUT localhost:9200/blogs/article/1 -d ' |
若添加成功就会返回以下信息:
{ |
对已存在的记录再进行 PUT 操作就会更新该记录,同时,该字段的_version和_result都会改变,_version会+1,_result会变为updated。
再通过curl localhost:9200/blogs/article/1,获取该文章的元数据,以及_source属性,存储的就是文章中定义的内容。
{ |
可通过curl localhost:9200/_cat/indices?v获取当前节点的索引信息
若要删除某个索引或类型或文档,都可通过curl -X DELETE localhost:9200/要删的资源删除。
简单搜索
curl localhost:9200/_search?pretty获取本节点的所有文档信息,并且返回结果不仅告知匹配了哪些文档,还包含了整个文档本身:显示搜索结果给最终用户所需的全部信息。?pretty会将 json 重新排版显示。
{ |
可通过_all字段进行指定文档或类型中的搜索,例如/_all/employee/_search?进行指定类型中搜索(所有索引的中的employee(如果存在))
?q=字段:值进行查询字符串(Query-string)搜索
curl localhost:9200/_search?q=title:article2 |
查询表达式搜索
使用的是 Elasticsearch 开发的 DSL(领域特定语言),基于 JSON 定义查询,能够构造复杂的查询语句。
不使用 Query-string 查询,而是通过请求体查询,请求会通过 Json 构造。
curl localhost:9200/_search -X GET -H "Content-Type: application/json" -d ' |
常用请求体搜索规则:
"query":{}表示开始查询,其中定义许多查询规则,会计算评分数量(相关度)_score
"bool":进行布尔匹配"must":包含"must_not":不包含
"match":普通匹配,若用空格隔开多个关键字,则 es 认为是或的关系,如果要同时满足多个关键词,即与关系,必须用bool查询"match_phrase":短语精确匹配"filter":过滤器,不会计算评分数量"range":匹配范围,例如:"range":{age":{"gt":30}}匹配 age 大于 30
"size":设置一次返回的结果数量,默认为 10 条。"from":设置移位,默认从位置 0 开始
# 已经alias curl_lo_g='curl -X GET -H 'Content-Type:application/json'' |
对于 filter 和 query 的区别:
- 大部分 filter 的速度快于query 的速度
- filter 不会计算相关度得分,且结果会有缓存,效率高
- 全文搜索、评分排序,使用 query
- 是非过滤,精确匹配,使用 filter
高亮搜索
能将搜索结果的要搜索的字符串高亮显示,
curl_lo_g ${LO_ES}/_all/employee/_search -d ' |
聚合
聚合 aggregations 用于生成基于数据的精细分析结果,类似 SQL 的group by。
Logstash
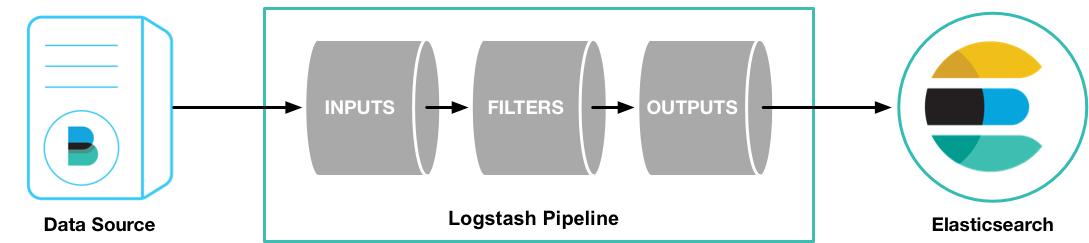
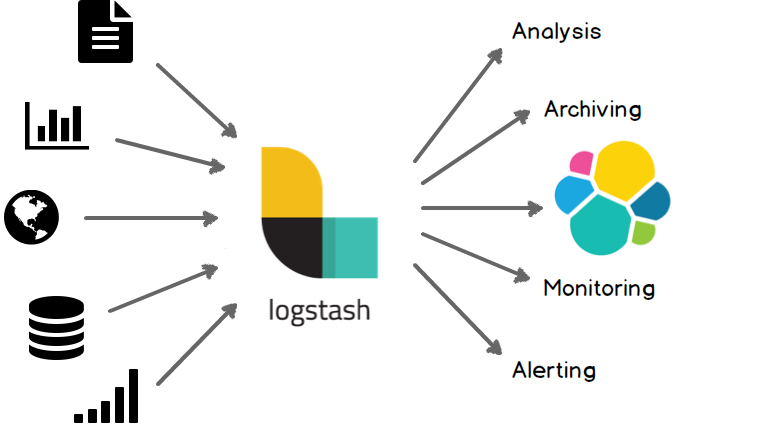
Logstash 是一个开源的服务器端数据处理管道(Pipeline),它可以同时从多个源中提取数据,对其进行转换,然后将其发送到数据存储(如 Elasticsearch)。支持丰富的 Input 和 Output 类型,能够处理各种应用的日志。
Logstash 对于每一行数据(称为 event)按流水线三个部分进行操作:
- input:负责产生事件(即数据),即数据源,如 syslog、数据库日志、web 日志、文件系统日志、java 的 log4j、网络日志、防火墙等各类日志,kafka、RabbitMQ 等消息队列,移动设备、智能家居、传感器、联网汽车等 IoT 数据,以及 Beats 能获取的数据。是必须配置
- filter:负责数据处理与转换,包括过滤,分类等操作。不是必须配置。
- output:负责数据的输出,可输出到数据分析或存储的软件,如 Elasticsearch,nagios,kibana 等数据处理软件。是必须配置
Logstash 开箱即用,包含许多聚合(aggregation)和突变(mutation),以及模式匹配(pattern matching),地理映射(geo mapping)和动态查找(dynamic lookup)功能。
Logstash 安装
下载 Logstash 包,版本为 6.4.1,解压到
/usr/local/logstash6.4进入 logstash 的
bin目录执行./logstash -e 'input{stdin{}} output{stdout{codec=>rubydebug}}',需要等待一段时间,期间会有信息,直到出现Successfully started Logstash API endpoint {:port=>9600},然后输入hello world即可看到以下信息。若要退出,按Ctrl+D。hello world
{
"message" => "hello world",
"host" => "VM_0_7_centos",
"@version" => "1",
"@timestamp" => 2018-09-26T11:09:10.781Z
}
docker 下载 Logstash:直接docker pull logstash即可。
docker 下启动 Logstash:首先要确保本地存放 pipeline 配置文件的目录存在。通过在该目录添加配置文件。或者直接-v ~/config:/usr/share/logstash/config可直接修改所有配置
docker run -it -v ~/pipeline:/usr/share/logstash/pipeline logstash
Logstash 配置文件:
logstash.yml:主配置文件pipelines.yml:管道的配置,包括 input,filter,outputjvm.options:JVM 配置文件log4j2.properties:log4j2 的配置startup.options:启动脚本选项文件,包含 Logstash 的变量。若要让 Logstash 按修改后的配置运行,需要重新用 root 运行bin/system-install导入参数。- 自定义的 Logstash 配置文件,一般以
.conf结尾,同样存放在配置文件目录中。
logstash 命令
logstash |
Logstash 如何工作
关闭 Logstash
可通过systemctl stop logstash或直接kill关闭。Logstash 有自己关闭过程,以达到安全地关闭:
- 首先停止所有的
input、filter、output插件 - 处理完所有管道中的事件
- 最后关闭 Logstash 进程
在处理过程中,以下的状况会影响关闭过程:
input插件以很慢的速度接收数据- 速度慢的
filter,如执行sleep(10000)的Ruby filter或执行非常繁重的查询的 Elasticsearch 过滤器。 - 一个断开连接的
output插件,等待重新连接以刷新正在进行的事件。
Logstash 有一个停顿检测机制(stall detection),可以在关闭过程中分析管道和插件的行为。此机制会对内部队列中的飞行事件(in-flight events)数量和繁忙的 worker 线程列表定期生成信息报告。
若要在 Logstash 关闭阶段直接强行关闭,可在主配置文件中设置pipeline.unsafe_shutdown值为true,但这样可能造成数据丢失,不安全。
Logstash 配置文件
logstash.yml
因为配置文件的语法是 YAML,所以有两种写法:
pipeline: |
配置文件也支持${}引用变量
如果使用命令的--modules指定模块,则配置文件中所有配置的模块都会被忽略。
模块的配置:
modules: |
所有配置参数:
node.name #节点名,默认为主机名 |
自定义 Logstash 配置文件
自定义的配置文件主要用于指定input、filter、output插件等管道参数。
配置文件支持的值类型:
列表 Lists:
[ ]中包含多个值。如path => ['XXX','XXX']布尔值 Boolean:指定
true或false字节 Bytes:是字符串字段,表示有效的字节单位。支持
SI(k M G T P E Z Y)和二进制(binary)(Ki Mi Gi Ti Pi Ei Zi Yi)单位。二进制单位基数为 1024,SI 单位基数为 1000。此字段不区分大小写,并接受值和单位之间的空格。编解码器 codec:表示数据的 Logstash 编解码器的名称。编解码器可用于输入和输出。例:
codec => json输入编解码器提供了一种在数据进入输入之前对其进行解码的便捷方式。
输出编解码器提供了一种在数据离开输出之前对数据进行编码的便捷方式。
使用输入或输出编解码器无需在 Logstash 管道中使用单独的过滤器。
哈希 Hash:键值对集合,多条键值对间使用空格间隔,而不是逗号
数字 Number:数字必须为浮点型或整型
密码 Password:密码必须是一个字符串,且该字符串应未被记录或打印
URI:可以是完整的 URL,也可以是类似邮件地址,如
user:pass@XXX.net,如果 URI 包含密码,则不会记录或打印 URI 的密码部分路径 Path:表示有效操作系统路径的字符串
字符串 String:必须用引号括住,可以是单引号或双引号
转义序列 Escape Sequences:默认不启用转义序列。如果要在字符串中使用转义字符,需要在
logstash.yml中设置config.support_escapes:true。
Logstash 日志
Logstash 的日志存放在LS_HOME/logs中,默认日志等级为INFO, Logstash 的日志框架基于Log4j 2框架,其大部分功能直接暴露给用户。
在调试问题时,尤其是插件问题时,一般将日志记录级别增加到DEBUG以获取更详细的消息。从 5.0 版本开始,可以在 Logstash 中配置特定日志子系统的日志记录。
Logstash 提供一个带有开箱即用设置的log4j2.properties文件,可以更改轮换策略,类型和其他 log4j2 配置。需要重启 Logstash 以应用该配置。
慢日志(Slowlog)用于报告在通过管道(pipeline)时花费不正常时间的事件的日志消息。慢日志同样存放在LS_HOME/logs中。可在主配置文件中添加 slowlog 的配置,如下:
slowlog.threshold.warn: 2s |
以上配置指定了触发慢日志的条件。在过滤器中处理超过 100ms 的事件会在慢日志中记录为 trace 等级的事件,超过 2 秒的事件会记录为等级为 warn 的事件
可通过curl -X GET localhost:9600/_node/logging?pretty获取关于日志的信息
curl localhost:9600/_node/logging?pretty |
可通过curl -X PUT localhost:9600/_node/logging?pretty -H 'Content-Type: application/json' -d '{...}'动态设置指定日志子系统的日志等级。例如:
curl -XPUT 'localhost:9600/_node/logging?pretty' -H 'Content-Type: application/json' -d ' |
则会在log4j2.properties配置中自动添加上该指定配置。若要重置已通过日志记录 API 动态更改的任何日志记录级别,需要通过将 PUT 请求发送到_node/logging/reset将所有日志记录级别都恢复为log4j2.properties文件中指定的值
curl -X PUT localhost:9600/_node/logging/reset?pretty
将其他任意日志导入 Logstash 的操作:编写一个 pipeline 配置文件test.conf,或直接在pipeline.yml添加
input { #设置input参数 |
启动 Logstash,bin/logstash -f config/test.conf。会不断获取 httpd 和 squid 的日志消息
{ |
若要将 elasticsearch 的日志都再导入 elasticsearch,可进行以下配置:
input { |
启动 Logstash 就会显示已导入 elasticsearch 的日志
{ |
Logstash 常用插件
默认的 Logstash 安装包括 Beats 输入插件。 Beats 输入插件使 Logstash 能够从 Elastic Beats 框架接收事件,任何与 Beats 框架一起使用的 Beat(如 Packetbeat 和 Metricbeat),也可以将事件数据发送到 Logstash。
Grok:是 Logstash 过滤器的基础,用于从非结构化数据中获取结构,具有丰富的集成模式,能快速处理 Web,系统,网络和其他类型的事件格式。Codecs:通常用于简化对 JSON 和多行事件等常见事件结构的处理。
Kibana
Kibana 是一个开源分析和可视化平台,旨在与 Elasticsearch 协同工作。可使用 Kibana 搜索,查看以及与存储在 Elasticsearch 索引中的数据进行交互,可以轻松地执行高级数据分析,并在各种图表(charts),表格(tables)和地图(maps)中可视化数据。
Kibana 是基于 JS 的 WEB 界面,在 Node.js 上运行,而官方在 Kibana 包中包含了必要的 Node.js 二进制文件,并且不支持针对单独维护的 Node.js 版本运行 Kibana,因此不需要单独搭建 Nodejs 环境。
应将 Kibana 配置为针对相同版本的 Elasticsearch 节点运行,即版本要一致。
注:从 V6.0.0 开始,Kibana 仅支持 64 位操作系统。
Kibana 安装
下载 Kibana 包,版本为 6.4.1,解压到/usr/local/kibana6.4
kibana 需要 elasticsearch 的开启才能正常使用,否则启动 kibana 会不断报错,进入 Kibana 后也会提示 status 为 red,无法正常使用,因此需要先启动 elasticsearch。开启后,进入 kibana 目录下bin执行kibana命令。需要等待一段时间直到出现信息[info][listening][server][http] Server running at http://localhost:5601。通过浏览器localhost:5601访问 kibana。
注:内存或 CPU 不足会将 Elasticsearch 杀死,Kibana 也就无法启动
Kibana 的文件结构:除了bin、config、data、plugins,kibana 还有以下目录:
node:node_modulesoptimize:存放透明的源代码。某些管理操作(例如,插件安装)导致源代码在运行中被重新传输。srcwebpackShims
可在浏览器访问localhost:5601/status查看 kibana 是否启动正常,插件是否加载正常,以及 kibana 的当前信息。
Kibana 配置
Kibana 只有一个配置文件KIBANA_HOME/config/kibana.yml。默认运行在 localhost 的 5601 端口。
常见配置:
server.port: 5601 #Kibana服务端口 |
Kibana 基本功能
添加 index 的管理
首先要在 elasticsearch 添加 index 数据
curl -X PUT -H "Content-Type: application/json" localhost:9200/tech/employee/1 -d ' |
然后刷新 kibana,进入 Management 中的 Kibana,选 Index pattern,并创建。
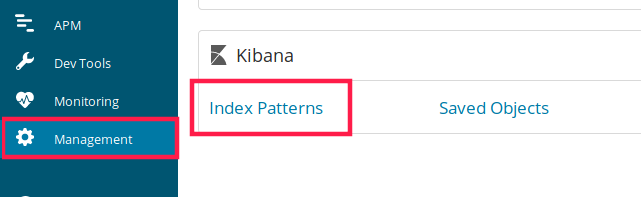
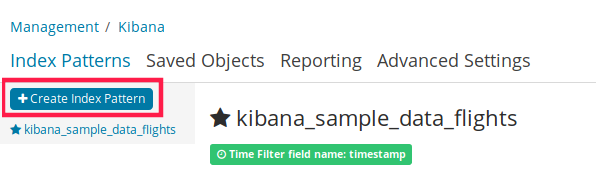
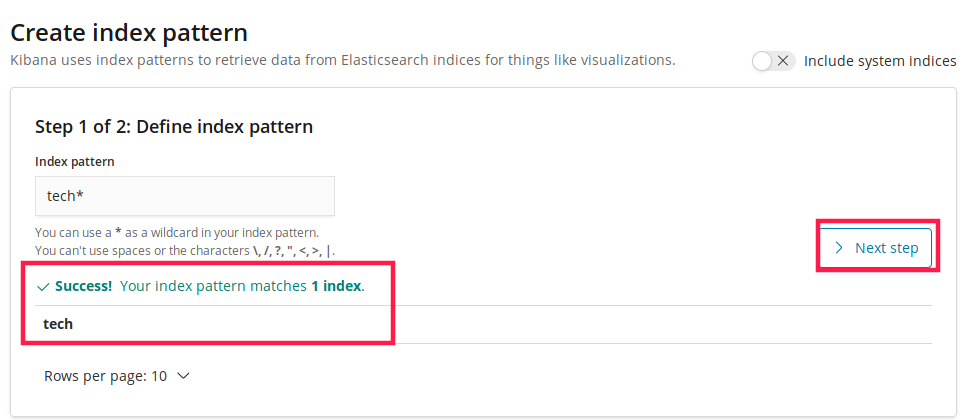
创建完成后,进入 Discover 菜单,可查看插入的数据
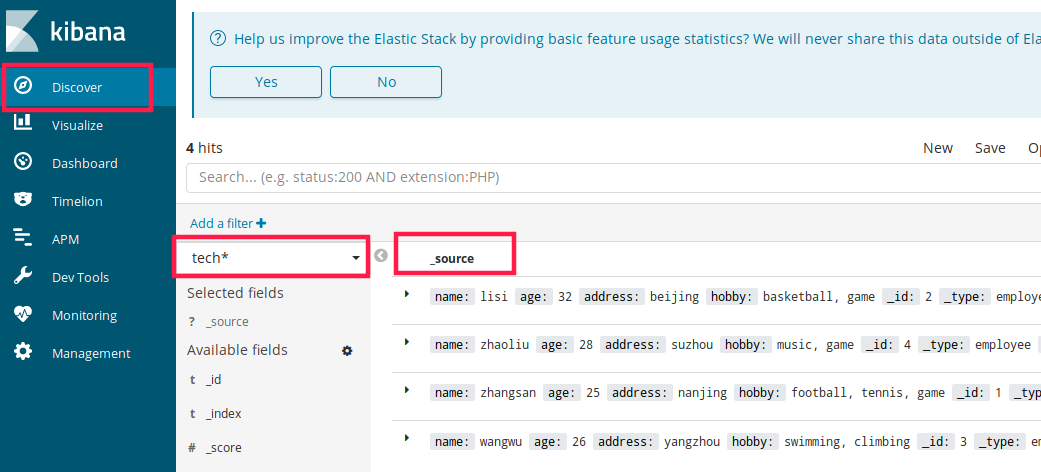
使用 kibana 提供的数据进行分析
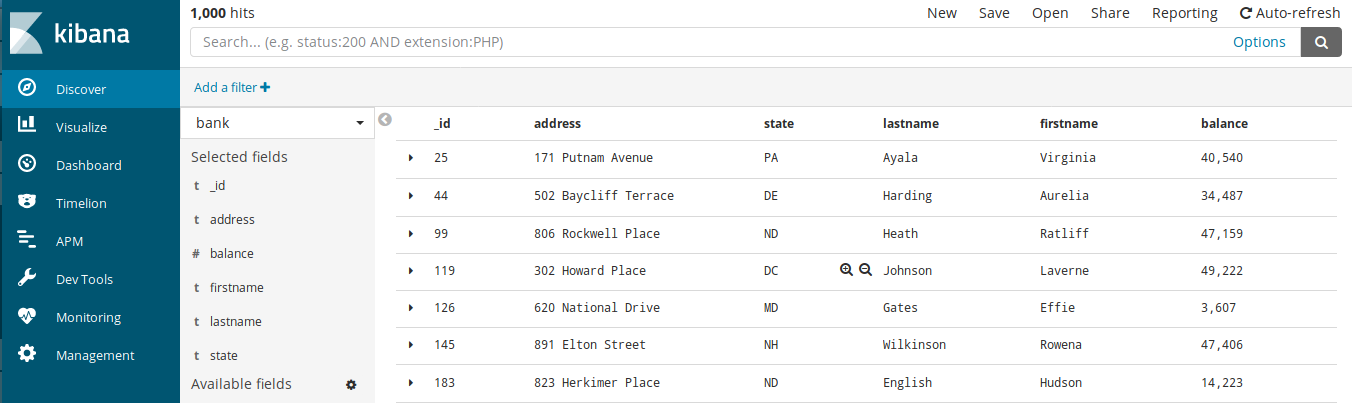
从kibana 文档中下载数据,可选择银行账户数据 account.json,
下载后通过以下操作导入 elasticsearch。开启 kibana,进入 Management 添加 index pattern,然后进入 Discover 菜单,选择 bank,添加要看的字段。
curl -H 'Content-Type: application/x-ndjson' -XPOST 'localhost:9200/bank/account/_bulk?pretty' --data-binary @accounts.json |
为数据创建报表,进入 Visualize 菜单,可根据需要选择报表形式,此处选 Pie 饼图,然后再选择 bank 即可进入定制界面。
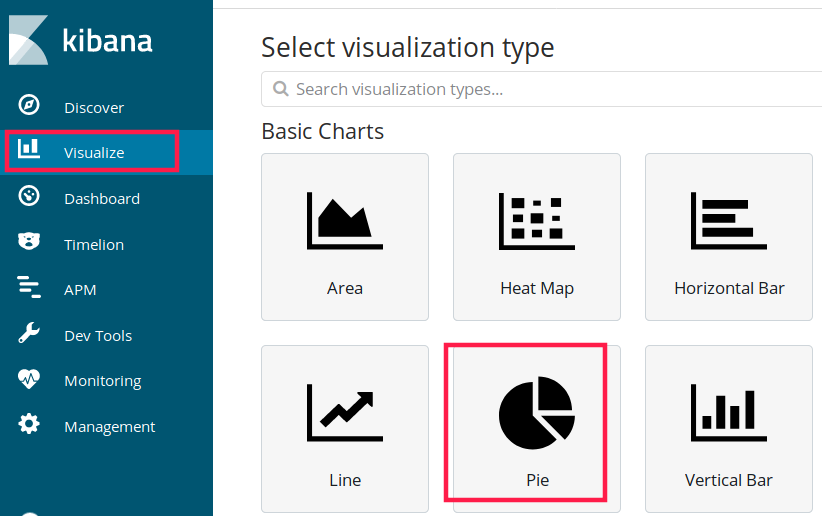
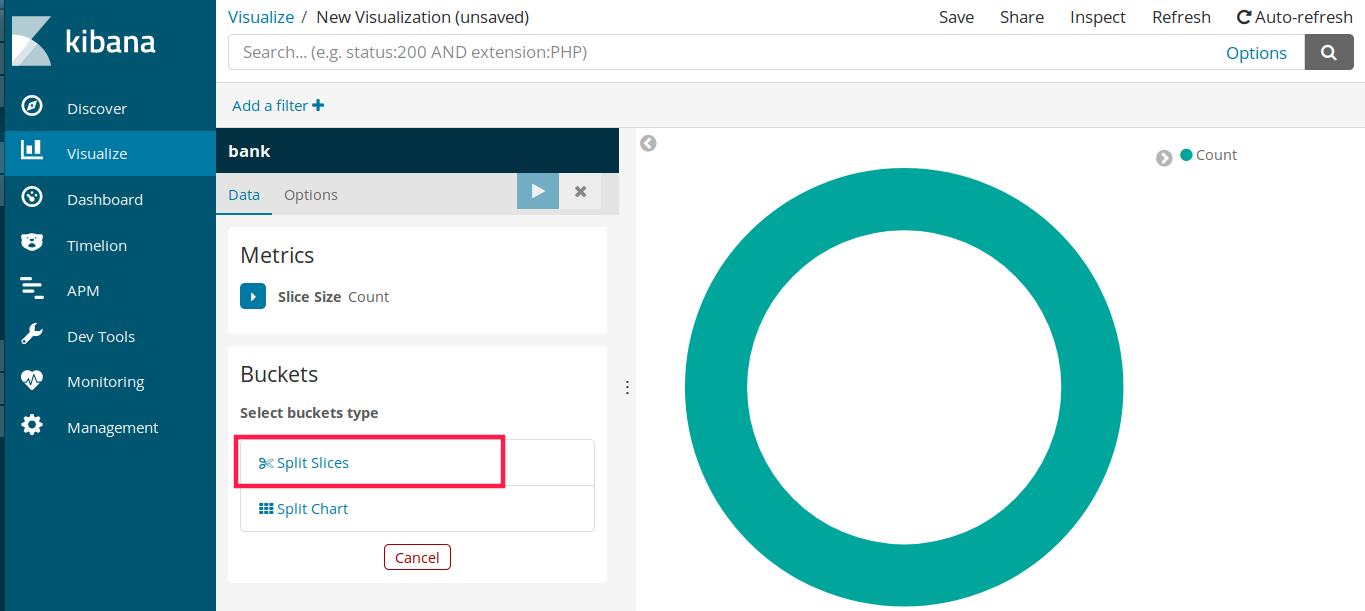
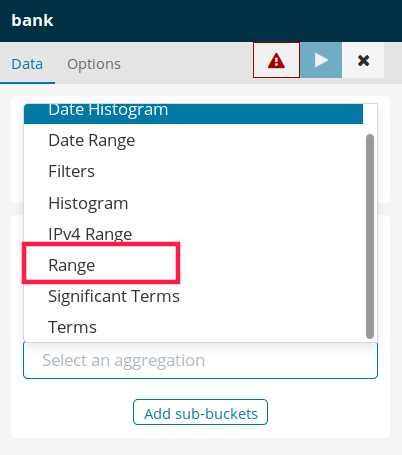
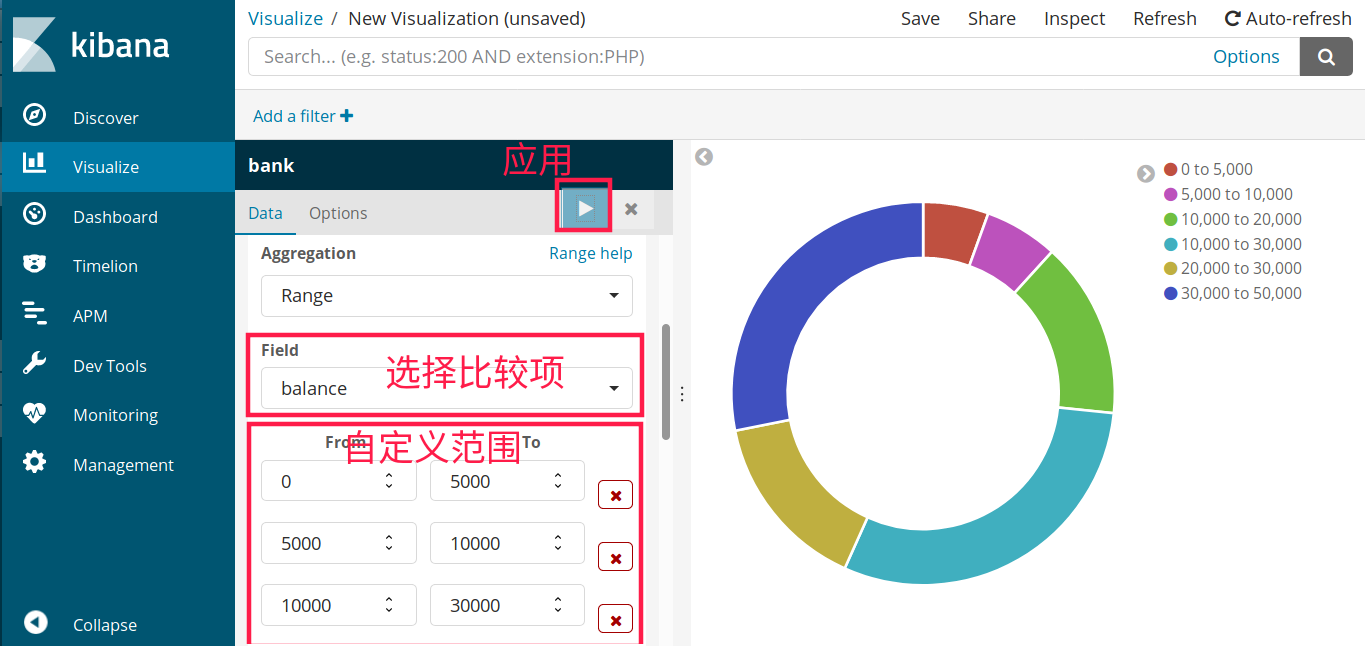
选择 split slices,然后在聚合(aggregation)中选择 range,然后进行自定义数据范围
ELK 架构
若环境的内存少,就在 es 配置文件添加以下配置
bootstrap.memory_lock: false 为避免内存与磁盘间的 swap,会损耗大量性能
bootstrap.system_call_filter: false
参考文章
每天 5 分中玩转 docker 容器技术