





LVS 原理
LVS(Linux Virtual Server)Linux 虚拟服务器是由章文嵩于 1998 年开发的负载均衡软件,提供传输层和应用层的负载均衡,传输层的负载均衡工具为 IPVS,应用层的负载均衡工具为 KTCPVS。
LVS 集群的通用体系结构
LVS 集群采用三层结构:
负载调度器(load balancer):整个集群的前端机,将网络请求无缝调度到真实服务器上,使服务器集群的结构对客户透明。因为所有的操作都是在 Linux 内核完成的,调度开销很小,所以具有很高的吞吐率。
服务器池(server pool):是一组真正执行客户请求的服务器。服务器池的结点数目是可变的,可以在服务器池中增加服务器来满足不断增长的请求负载。对大多数网络服务来说,请求间不存在很强的相关性,请求可以在不同的结点上并行执行。
共享存储(shared storage):为服务器池提供一个共享的存储区,通常是数据库、网络文件系统或者分布式文件系统,这样很容易使得服务器池拥有相同的内容,提供相同的服务。需要一个分布式锁管理器(Distributed Lock Manager)来保证应用程序在不同结点上并发访问的一致性。
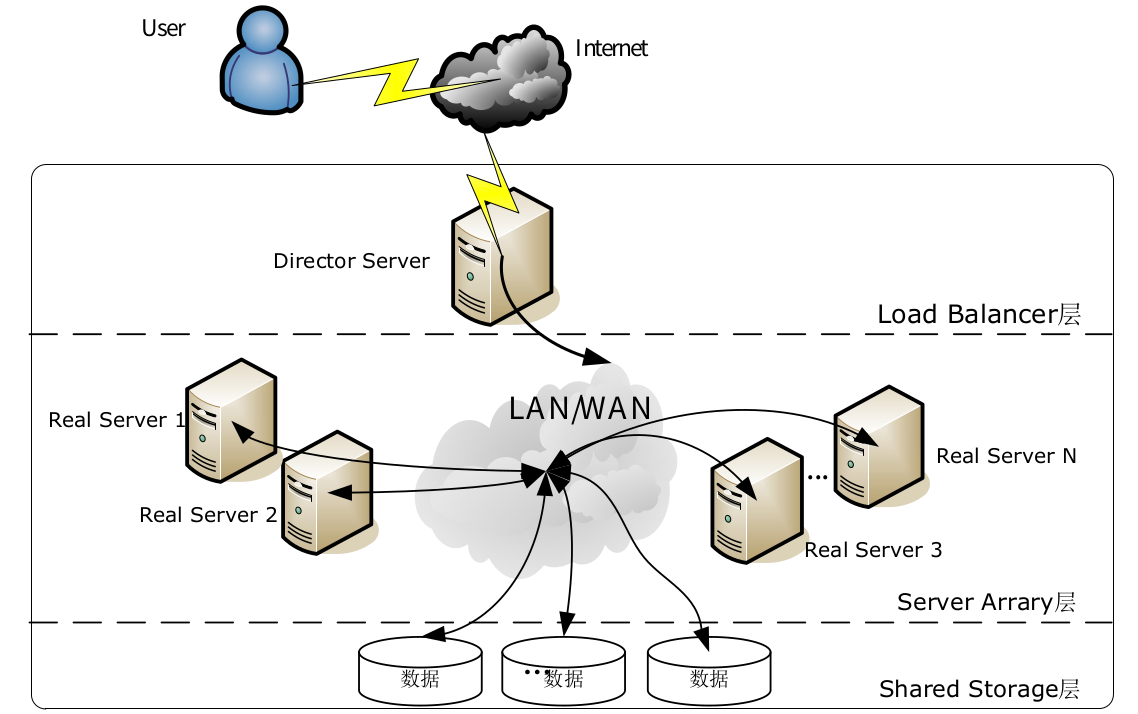
前端负载均衡器称为 Director Server(DR),后端的实际服务器称为 Real Server(RS),IP 虚拟服务器软件称为 IP Virtual Server(IPVS),IPVS 工作在 Linux 内核中。在调度器的实现技术中,IP 负载均衡技术的效率是最高的。
LVS 的几种 IP 地址
- VIP:virtual IP,DR 上接收外网数据包的网卡 IP 地址
- DIP:director IP,DR 上转发数据包到 RS 的网卡 IP 地址
- RIP:real IP,RS 的 IP 地址
- CIP:client IP,客户端 IP 地址
为什么要用共享存储?
共享存储是可选的,但若网络服务需要相同的内容,应该使用共享存储,否则无共享结构的代价会很大,每台服务器需要一样大的存储空间,任何更新需要涉及每一台服务器,系统的维护代价会非常高。分布式文件系统提供良好的伸缩性和可用性,分布式文件系统在每台服务器使用本地硬盘作 Cache,可以使得访问分布式文件系统的速度接近于访问本地硬盘。
如何实现高可用性?
调度器上有资源监测进程时刻监视各个服务器结点的健康状况,当服务器对ICMP ping 不可达时或者网络服务在指定的时间内没有响应时,资源监测进程会通知内核将该服务器从调度列表中删除。一旦监测到服务器恢复工作,通知调度器将其加入调度列表,管理员也可通过命令随时向调度列表添加或移除服务器。
调度器存在单点故障问题,因此需要对调度器进行主从备份,并用 HeartBeat 机制进行主从故障监测。当从调度器不能听得主调度器的心跳时,从调度器通过 ARP 欺骗 (Gratuitous ARP)来接管集群对外的 VIP,同时接管主调度器的工作来提供负载调度服务。当主调度器恢复后,有两种恢复机制。第一种为主调度器自动变成从调度器(类似抢占),另一种为从调度器释放 VIP,主调度器收回 VIP 继续提供负载调度服务。
当主调度器失效时,主调度器上所有已建立连接的状态信息将丢失,已有连接会中断。 客户需要重新连接从调度器,从调度器才会将新连接调度到各个服务器上。因此,调度器在内核中实现了一种高效同步机制,将主调度器的状态信息及时同步到从调度器。当从调度器接管时,绝大部分已建立的连接会持续下去。
三种 IP 负载均衡技术
VS/NAT:调度器重写请求报文的目标地址,根据预设算法,将请求分派给实际服务器,实际服务器在响应报文通过调度器时,报文的源地址被重写,再返回给客户。
优点: 节约 IP 地址,能对内部进行伪装
缺点: 效率低,返回给请求方的流量需经过 DR 且请求和响应报文都要 DR 进行地址的重写,当客户端请求增多时,DR 的处理能力会成为瓶颈
完整过程:- PC 向调度器发送请求报文,调度器收到后根据调度算法选择后端的实际服务器,将报文中目的 IP 与目的端口改写为实际服务器的 IP 地址与端口,并进行转发。
- 实际服务器收到后,进行处理,将结果返回给调度器
- 调度器再将源 IP 地址与源端口改回为调度器的 IP 和端口,回复给 PC。
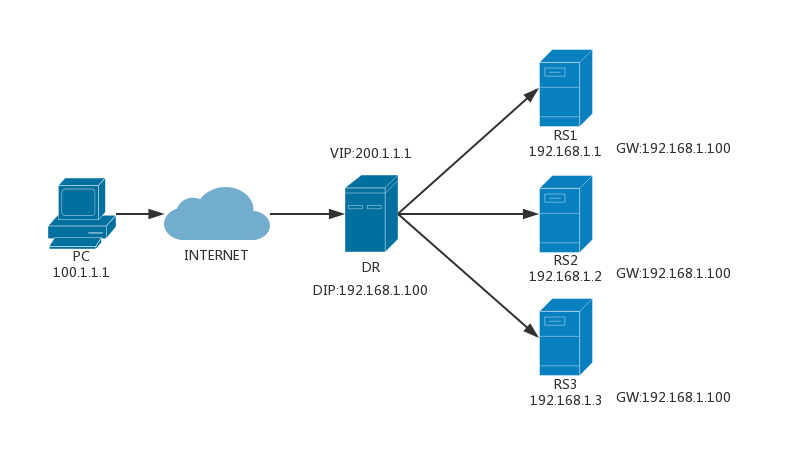
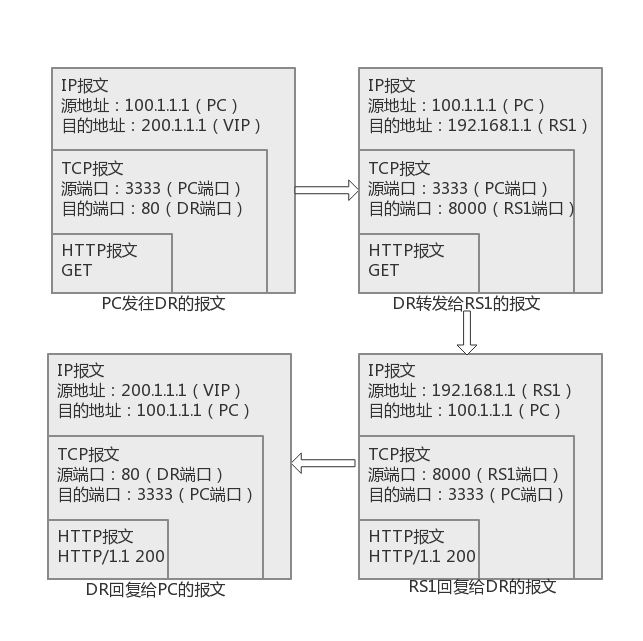
数据包流向:客户端–>调度器–>实际服务器–>调度器–>客户端VS/TUN(IP Tunneling):调度器将请求报文通过 IP 隧道转发到实际服务器,实际服务器将响应报文直接回复给客户,调度器仅需处理请求报文,将请求报文的地址重写,无需重写响应报文的地址,极大解放了调度器,集群系统的最大吞吐量能提高 10 倍。
IP 隧道技术:又称为 IP 封装技术,可以将带有源和目标 IP 地址的数据报文使用新的源和目标 IP 进行第二次封装,这样这个报文就可以发送到一个指定的目标主机上
由于多个 RS 都共享一个隧道 IP(为 VIP),所以需要通过 ARP 进行 IP 地址解析出 MAC,而为了不让 RS 响应 ARP 请求导致出现错误,必须对 RS 进行抑制操作,这样只有 DR 进行 ARP 响应,也就让 PC 认为 DR 就是实际服务器。
注: 由于调度器不会对 IP 报文进行修改,所以 TCP 报文中的目的端口也不会修改,因此要求 RS 与 DR 的端口号必须一致
完整过程:
- PC 发送请求给调度器,调度器进行调度算法选择后端的实际服务器,将原报文进行第二次封装,源地址变为 DIP,目的地址变为 RIP,然后通过 IP 隧道发给指定实际服务器。
- 实际服务器处理完数据后直接回复给 PC
实际服务器的 RIP 和 DR 的 DIP 可以不处于同一物理网络中,且 RIP 必须可以和公网通信,即集群节点可以跨互联网实现。
实际服务器的隧道接口上需要配置 VIP 地址,以便接收 DR 转发的数据包,以及作为响应报文的源 IP。
DR 给 RS 时需要借助隧道,隧道外层的 IP 头部的源 IP 是 DIP,目标 IP 是 RIP。而 RS 响应给客户端的 IP 头部是根据隧道内层的 IP 头分析得到的,源 IP 是 VIP,目标 IP 是 CIP。这样客户端就无法区分这个 VIP 到底是 DR 的还是服务器组中的。VS/TUN 模式一般会用来负载调度缓存服务器组,这些缓存服务器一般放置在不同网络环境,可以就近返回数据给客户端。在请求对象不能在缓存服务器本地找到的情况下,缓存服务器要向源服务器发请求,将结果取回,最后将结果返回给客户。
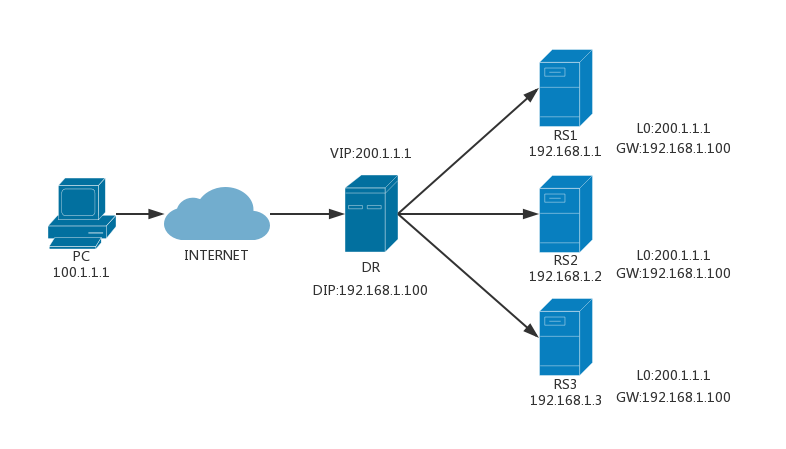
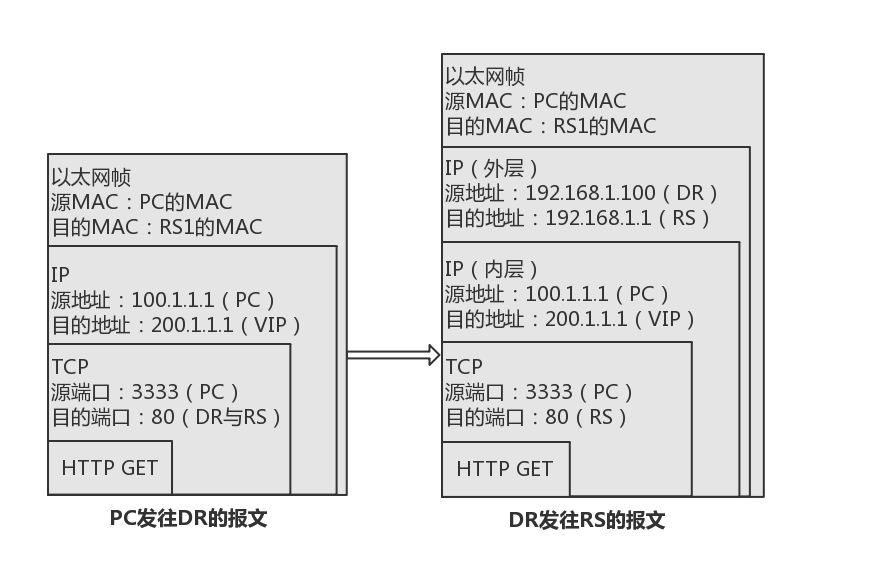
数据包流向:客户端–>调度器–>实际服务器–>客户端VS/DR(Direct Routing):与 VS/TUN 类似,但调度器改写的是数据包的目的 MAC 地址,通过链路层进行负载分担。此法没有 IP 隧道的开销,但要求调度器与实际服务器必须在同一网段,也就是说 RIP 可用公网地址。
完整过程:
- PC 向调度器发送请求,调度器根据调度算法选择后端实际服务器,将数据帧的目的 MAC 改写为该实际服务器的 MAC 地址,并转发。
- 实际服务器收到后处理完数据后直接将结果回复给 PC
注:因为与 VS/TUN 类似,直接修改以太网帧,所以对于 IP 报文不会做修改,因此RS 的端口号必须与 DR 一致。且RS 上必须配置 VIP(通过配置环回口 IP 地址),VIP 为网卡别名的 IP 地址,仅用于回复数据包时使用作为源地址,不能用于通信。由于流出接口为 RIP 所在网卡接口,因此源 MAC 地址为 RIP 所在接口的 MAC 地址。且并不支持端口映射。
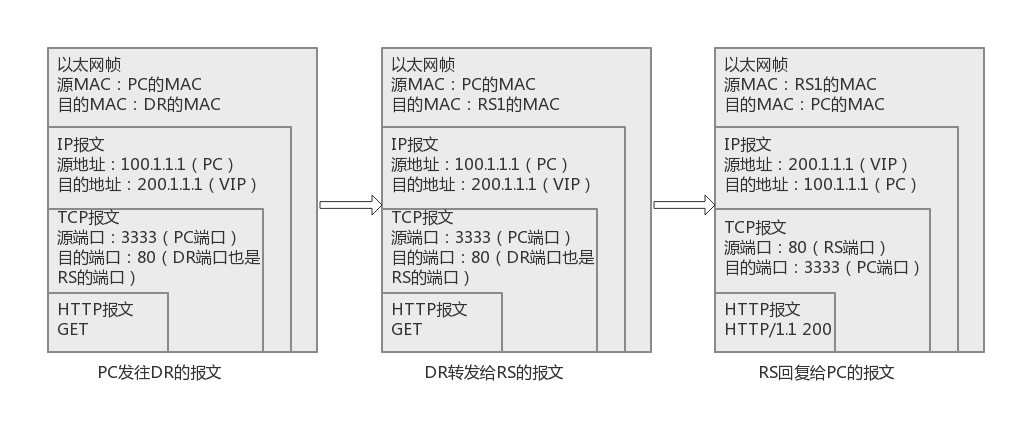
数据包流向:客户端–>调度器–>实际服务器–>客户端
三种模式的比较
DR 和 TUN 模式的性能高于 NAT,因为不需要 DR 对响应报文的操作
DR 性能高于 TUN,因为不需要维护 IP 隧道
DR 中调度器和实际服务器必须在同一个网段中,TUN 可实现跨网段负载均衡。
只有 NAT 支持端口映射,DR 与 TUN 都不支持。
为什么 VS/TUN 与 VS/DR 要在环回口 L0 上配置 VIP,能不能在出口网卡上配置 VIP?
在环回口上配置 VIP 使得 RS 能通过路由收到请求数据包,并将结果返回给客户。不可以将 VIP 配置在出口网卡上,否则真实服务器会响应客户端的 ARP 请求,客户端上的 ARP 表就会记录真实服务器的 MAC,造成混乱,LB 就失效了。必须保证路由器只保存 DR 上的 VIP 对应的 MAC,即只允许 DR 进行 ARP 响应。
在环回口配置 VIP 后,还需要设置arp_ignore=1和arp_announce=2来隐藏 RS 上的 VIP。应该在配置 VIP 之前就设置 arp 参数,防止配置 VIP 后、设置 arp 抑制之前被外界主机发现。
arp_ignore:接收到 ARP 请求时的响应级别。默认为 0。
- 0:响应目的地址是本地任意网卡上的所有 IP 地址的包
- 1:只响应目的地址恰好是入网卡的 IP 地址的包
arp_announce:将自己的地址向外通告时的通告级别。默认为 0。
- 0:使用本地任意接口上的任意地址向外通告
- 1:尽量避免使用本地属于对方子网的 IP 地址向外通告
- 2:总是使用最佳本地地址向外通告
arp_announce 为 2 的含义:在此模式下将忽略这个 IP 数据包的源地址并尝试选择能与该地址通信的本地地址。首要是选择所有网络接口的子网中包含该数据包目标 IP 地址的本地地址,如果没有发现合适的地址,将选择当前的发送网络接口或其他有可能接收到该 ARP 回应的网络接口来进行发送。
且这两项对所有参与集群调度的网卡都要设置
sysctl -w net.ipv4.conf.all.arp_ignore=1 |
IPVS 如何解决 HTTPS 连接问题?
当客户访问 HTTPS 服务时,会先建立一个 SSL 连接,来交换对称公钥加密的证书并协商一个 SSL Key,来加密以后的会话。在 SSL Key 的生命周期内,后续的所有 HTTPS 连接都使用这个 SSL Key,所以同一客户的不同 HTTPS 连接也存在相关性。IPVS 调度器提供了持久服务的功能,使得在设定的时间内,来自同一 IP 地址的不同连接会被发送到集群中同一个服务器结点,可以很好地解决客户连接的相关性问题。
可伸缩的缓存服务
调度器一般使用 IP 隧道方法(VS/TUN)来架构缓存集群,因为缓存服务器可能在不同地方,而调度器与缓存服务器池可能不在同一个物理网段。若请求对象不能在本地找到,缓存服务器会向源服务器发请求,将结果取回并返回给客户。
使用此方法,调度器只调度网页缓存服务器,而缓存服务器将响应数据直接返回给客户,调度器只需要调度一次请求,其余三次都由缓存服务器直接访问 Web 服务器完成。
缓存服务器间有专用的组播通道,通过 ICP(Internet Cache Protocol)协议交互信息。当一台 Cache 服务器在本地硬盘中未命中当前请求时,它可以通过 ICP 查询其他 Cache 服务器是否有请求对象的副本,若存在,则从邻近的 Cache 服务器取该对象的副本,这样可以进一步提高 Cache 服务的命中率。
可伸缩邮件服务
服务器池有 LDAP 服务器和一组邮件服务器,调度器将 SMTP、POP3、IMAP4 和 HTTP/HTTPS 请求流负载较均衡地分发到各邮件服务器上。系统中可能的瓶颈是 LDAP 服务器,可对 LDAP 服务中 B+树的参数进行优化。
若分布式文件系统没有多个存储结点间的负载均衡机制,则需要相应的邮件迁移机制来避免邮件访问的倾斜。
LVS 两种调度方式与八种算法
两种调度方式
- 静态调度:仅根据调度算法进行调度,不管实际服务器的系统负载
- 动态反馈调度:会根据实际服务器的系统负载及性能,计算出可以调度的服务器对象
八种算法
- 静态调度
- 轮询(Round Robin):调度器将请求根据调度算法按顺序轮流分配到实际服务器。调度器均等地对待每一台服务器,不管服务器上实际的连接数和系统负载。
- 加权轮询(Weighted Round Robin):根据实际服务器的不同处理能力调度访问请求。使处理能力强的服务器处理更多访问流量,调度器自动询问实际服务器负载情况,并动态调整权值。
- 目标地址散列(Destination Hashing):将请求的目标地址作为散列键,从静态分配的散列表中找出对应的服务器。
- 源地址散列(Source Hashing):将请求的源地址作为散列键,从静态分配的散列表中找出对应服务器。
- 动态反馈调度
- 最少连接(Least Connections):动态将网络请求调度到已建立的连接数最少的服务器上。计算方法:活跃连接数 active*256+非活跃连接数 inactive
- 加权最少连接(Weighted Least Connections):当集群中服务器性能差异较大的情况下使用。具有较高权值的服务器将承受较大比例的活动连接负载。调度器可以自动问询真实服务器的负载情况并动态调整权值。此算法为默认调度算法。 计算方法:(active*256+inactive)/weight
- 基于局部性最少连接(Locality-Based Least Connections):针对 IP 地址的负载均衡,用于缓存集群系统。根据请求的 IP 地址找出该目标 IP 地址最近使用的服务器,若该服务器不可用,则用最少连接原则选出一个可用的服务器。该算法维护的是从一个目标 IP 地址到一台服务器的映射。
- 带复制的基于局部性最少连接(Locality-Based Least Connections with Replication):针对 IP 地址的负载均衡,根据请求的目标 IP 地址找出与之对应的服务器组,按最小连接原则选出一台服务器。若该服务器超载,就在集群中按最小连接原则选出一台服务器,添加到服务器组中。该算法维护的是从一个目标 IP 地址到一组服务器的映射。
LVS 持久连接
无论使用哪种算法,LVS 持久化都能实现在一定时间内,将来自 统一客户端请求派发到此前访问过的 RS。
需要持久连接的原因:若连接是基于 SSL 的,则在建立连接时需要交换密钥,认证 CA 等操作,若每次刷新就又分配别的 RS,则会造成资源浪费,速度变慢,因此需要持久连接。
每一次建立连接后,DR 会在内存缓冲区中为每一个客户端与 RS 建立映射关系(该记录也称 “持久连接模板” ),并且能做到对同一客户端的所有请求(不局限于一个服务)都定位到一台 RS。
持久连接分类:
PPC(Persistent Port Connections)持久端口连接:将来自同一客户端对同一个集群的请求(同一端口)都定向到先前访问的 RS 上。
PCC(Persistent Client Connections)持久客户端连接:将来自同一客户端对同一个集群所有端口(即所有服务)的请求都定向到先前访问的 RS 上。
PNMPP(Persitent Netfilter Marked Packet Persistence)持久防火墙标记连接:通过防火墙策略,将对某类服务几个不同端口的访问定义成一类。
先对某一特定类型的数据包打上标记,然后再将基于某一类标记的服务送到后台的 RS 上去,后台的 RS 并不识别这些标记。将持久和防火墙标记结合起来就能够实现端口姻亲功能,只要是来自某一客户端的对某一特定服务(可以是不同端口)的访问都定向到同一台 RS 上。
KeepAlived 原理
KeepAlived 用于 RS 的健康状态检查与 LB 主从之间的故障转移(Failover)实现。 Keepalived 实现了一组健康检查器,根据其健康状况动态自适应地维护和管理负载平衡的服务器池,支持4、5、7 层协议的健康检查。使用VRRP 实现高可用性,VRRP 是路由器故障转移的基础实现方法。此外,keepalived 实现了一组到 VRRP 有限状态机的挂钩,提供低级别的高速协议交互。每个 Keepalived 框架可以独立使用或一起使用,以提供弹性基础设施。
Keepalived 采用纯 ANSI/ISO C 编写,围绕一个中央 I/O 多路复用器提供实时网络设计(Realtime Networking Design)。设计重点是在所有元素之间提供均匀的模块化功能。
为了确保鲁棒性和稳定性,守护进程 keepalived 分为 3 个不同的进程:
- 一个精简的父进程负责分支子进程的监控
- 两个子进程,一个负责VRRP 框架,另一个负责健康检查
每个子进程都有自己的调度 I/O 多路复用器,这样 VRRP 调度抖动得到了优化,因为 VRRP 调度比健康检查更关键。这种拆分设计可最小化健康检查外部库的使用情况,并将其自身行为降至最低,使主机闲置,从而避免由其本身造成的故障。
父进程监视框架称为Watchdog,每个子进程打开一个套接字,当守护进程引导时,父进程连接到套接字并向子进程周期(5s)发送 hello 包。若父进程无法向子进程套接字发送 hello,则只要重启子进程即可。
Watchdog 设计的优点:
从父进程发送到子进程的 hello 数据包通过 I/O 多路复用器调度程序完成,这样可以检测到子进程调度框架中的死循环并能通过使用 sysV 信号来检测死亡的子进程。
Keepalived 使用四个 Linux 内核组件:
- LVS 框架:使用 getsockopt 和 setsockopt 调用来获取和设置套接字上的选项。
- Netfilter 框架:支持 NAT 和伪装(Masquerading)的 IPVS 代码。
- Netlink 接口:设置和删除网络接口上的 VRRP 虚拟 IP。
- 组播:通过组播地址224.0.0.18发送 VRRP 通告。
LVS 与 KeepAlived 搭建
首先在 DR 上安装依赖工具包libnl3-devel、popt-static,然后安装ipvsadm。ipvsadm是 ipvs 的命令行管理工具,可以定义、删除、查看 virtual service 和 Real Server 的属性。
可通过grep -i 'ip_vs' /boot/config-内核版本号查看是否内核中编译了 IPVS 功能
ipvsadm 的下载地址
也可以通过 yum 安装,安装完成后启动并设置开机自启systemctl enable ipvsadm,systemctl start ipvsadm
ipvsadm 命令
ipvsadm选项中,大写选项管理虚拟服务virtual service,小写选项管理关联了虚拟服务的真实服务器RealServer |
NAT 模式搭建
实验环境:
- Client:192.168.205.151
- VIP:192.168.205.152
- DIP:172.16.184.130
- RIP1:172.16.184.131
- RIP2:172.16.184.132
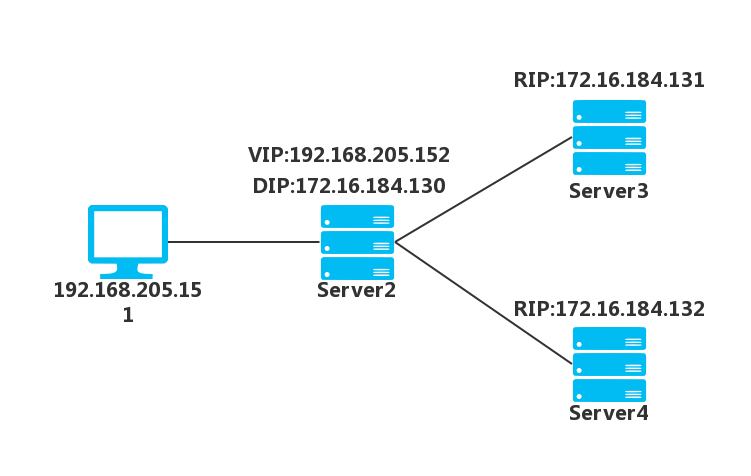
Client 和 RS 都采用单网卡,但非同一网段。DR 采用双网卡,一张连接 Client,一张连接 RS。且此实验 RS 要用 host-only 网卡,需要设置网关
route add default gw 172.16.184.130
确保 Server3 和 Server4 的网关配置生效,否则无法给 Client 连接。
注:一定要将网卡配置为静态 IP 地址,不能使用 DHCP 获取,否则配置的网关会自动消失。
# route -n |
Client 请求过程:Client 向 DR 发请求包,VIP 接收,经过 ip_forward 转发到 DIP,然后根据算法选择 RS,将数据包发往 RS。
RS 响应过程:RS 向 DR 发响应包,DR 的 DIP 接收响应包,经过 ip_forward 转发到 VIP,最后将包回复给 Client。
因为 VIP 与 DIP 不是一个网段,所以 DR 上要开启 ip_forward,并且要注意 iptables 与 ipvs 不可同时配置。
echo "net.ipv4.ip_forward=1" >> /etc/sysctl.conf && sysctl -p
在 Server2 上配置:
ipvsadm -A -t 192.168.205.152:80 -s rr |
通过ipvsadm -nL查看 LVS 服务
# ipvsadm -Ln |
LVS 需要服务器间的时间同步,因此需要在 Server2 上配置 chronyd 服务。修改/etc/chronyd.conf,添加更新源。然后chronyc sources -v自动同步。
然后在 Server3 和 Server4 的 chronyd 配置文件中修改更新源server 192.168.205.152 iburst并自动更新。
在 Client 上多次访问192.168.205.152,因为选择的算法是轮询,所以会有以下现象。
# curl 192.168.205.152 |
在 Server2 上查看ipvsadm -L --stats
# ipvsadm -L --stats |
修改为 wrr 算法。在 Server2 上修改 IPVS 规则:
ipvsadm -E -t 192.168.205.152:80 -s wrr |
Client 上访问几次,再在 Server2 上查看,可发现访问 Server3 和 Server4 的包数量比例大约为 5:3
# ipvsadm -L -n |
DR 模式搭建
环境:
- DR 的 VIP:172.16.246.140
- DIP:172.16.246.134
- RIP1:172.16.246.135
- RS1 的 VIP:172.16.246.140
- RIP2:172.16.246.136
- RS2 的 VIP:172.16.246.140
一定要确保 DR 和 RS 在同一个交换机上,即都在同一个网段,以及 VIP 都要在同一个网段。
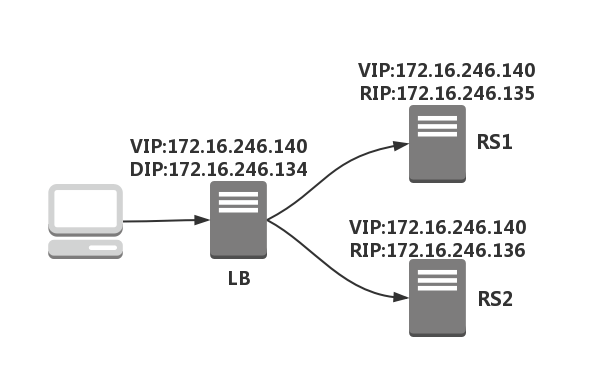
首先在 DR 上配置,创建网卡别名ens33:0
# ifconfig ens33:0 172.16.246.140 netmask 255.255.255.0 broadcast 172.16.246.255 up # 这是临时的,切要确保地址都是静态的,否则过一段时间配的地址会自动删除 |
在两个后端 RS 服务器上pingDR 上的这两个地址,测试能够联通
然后在 RS 上配置 IP 地址,也确保为静态 IP。并且需要将 RS 的内核参数arp_ignore和arp_announce分别调整。
sysctl -w net.ipv4.conf.all.arp_ignore=1 |
然后在环回口上配置 VIP,保证 DR、RS 的 VIP 相同。
ifconfig lo:0 172.16.246.140 netmask 255.255.255.255 boardcast 172.16.246.140 up |
并且配置路由
route add -host 172.16.246.140 dev lo:0 |
在 DR 上篇配置路由route add -host 172.16.246.140 dev ens33:0
确保 RS 与 DR 的防火墙都放行了 http 以及对应端口。
在 DR 上配置 LVS
ipvsadm -A -t 172.16.246.140:80 -s wlc |
在宿主机上测试
# curl 172.16.246.140 |
持久化配置
仍使用 DR 配置的实验环境
只需要配置一条ipvsadm -E -t 172.16.246.140:80 -p 600
ipvsadm -L -n |
在宿主机上访问172.16.246.140,访问到的是 RS2(即172.16.246.136),在查看 DR 上信息
ipvsadm -L -n --persistent-conn |
Keepalived 配置
实验环境:
- DR:
172.16.246.134 - DR-Backup:
172.16.246.133 - RS1:
172.16.246.135 - RS2:
172.16.246.136
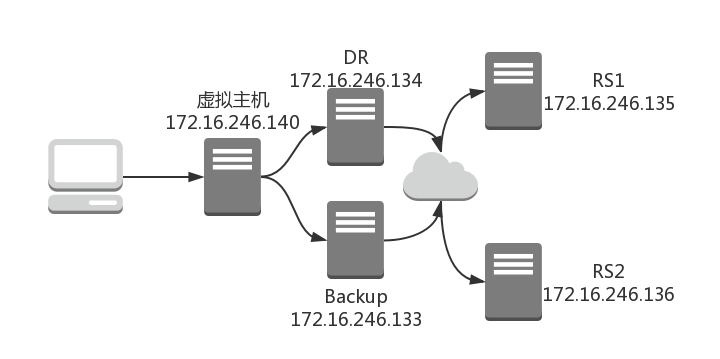
需要在 DR 和 DR-backup 上安装 keepalived,可直接通过 yum 安装。
设置独立的 keepalived 日志,因为默认 keepalived 日志是记录在/var/log/messages中的。修改/etc/sysconfig/keepalived
# 有以下配置项 |
然后在/etc/rsyslog.conf中添加local0的配置local0.* /var/log/keepalived.log,重启 rsyslog 服务即可。
keepalived 的配置文件/etc/keepalived/keepalived.conf,修改前最好备份。配置文件分为是三个部分:全局配置、VRRPd 配置、LVS 配置
# 此配置截取自默认配置,仅用于说明参数 |
在 DR 上的配置
global_defs { |
可以将 DR 上的该配置文件传到 Backup 上,修改配置。还要修改router_id的配置,因为router_id用于标识不同服务器
# 只要修改以下配置 |
都启动 keepalived,使用命令keepalived或者systemctl start keepalived即可
可查看日志文件/var/log/keepalived.log
s1 Keepalived[42451]: Starting Healthcheck child process, pid=42452 |
Keepalived 配置会自动创建 ipvs 策略,此时看ipvsadm -L已是 keepalived 的配置了
# ipvsadm -L -n |
宿主机上访问服务
> curl 172.16.246.140 |
此时停止 RS2 的 httpd 服务,再访问服务
> curl 172.16.246.140 |
恢复 RS2 服务,在 DR 上停止 keepalived。再访问服务,仍能访问,keepalived 配置成功。
将后端 RS 的 httpd 全部关闭,然后再次访问,就会访问到 DR 的页面。
几种时间间隔:
advert_int:vrrp 主备间发送和接收心跳信息的时间间隔delay_loop:健康状态检查的时间间隔connect_timeout:连接 RS 的超时时间nb_get_retry:一个节点不健康的判定重试次数delay_before_retry:判定某节点可能宕机后等待的时间,之后重试连接
几种健康检查:
TCP_CHECK:TCP 连接来检查后端 RS 是否健康HTTP_GET:获取指定页面检查 RS 是否健康(通过匹配 digest、status_code)SSL_GET:类似 HTTP_GET,但使用的 HTTPSMISC_CHECK:加载自定义健康状态检查脚本来检查对象是否健康(脚本的返回值需要是 0 或 1)DNS_CHECK:通过 DNS 检查 RS 是否健康
若出现两台服务器争抢同一 IP 资源时,要先排查两个地方:
- 主备两台服务器之间是否正常通信,如果不正常是否有 iptables 防火墙阻挡
- 主备两台服务器对应的 keepalived.conf 配置是否出错
解决裂脑的常见方案:
- 如果开启防火墙,一定要放行心跳信息,一般通过允许 IP 段解决
- 拉一条以太网网线作心跳线冗余
- 通过监控软件监测裂脑
- 若备节点出现 VIP,且主节点完好正常,则说明发生裂脑了。
Keepalived 双实例双主模式配置
多实例,即业务 A 在 hostA 上是主模式,在 hostB 上是备模式,而业务 B 在 hostA 上是备模式,在 hostB 上是主模式。
实验环境:
172.17.1.128:业务 A 的 master,业务 B 的 backup172.17.1.129:业务 A 的 backup,业务 B 的 master- 业务 A 的 VIP:
172.17.1.100 - 业务 B 的 VIP:
172.17.1.200
172,17.1.128 的配置:
vrrp_instance BusinessA { |
172.17.1.129 的配置:
vrrp_instance BusinessA { |
重新启动 keepalived,查看ip addr
ens32: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000 |
Nginx 负载均衡配合 Keepalived
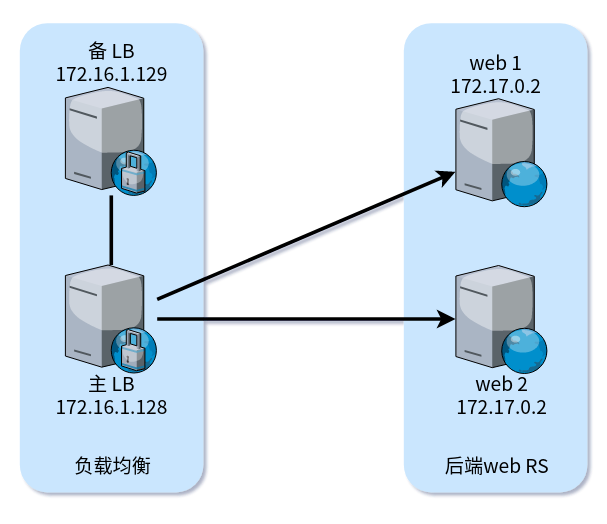
实验环境:
- LB 1:
172.16.1.128 - LB 2:
172.16.1.129 - 业务 A VIP:172.16.1.100
- 业务 B VIP:172.16.1.200
- web RS1:172.17.0.2
- 业务 A:80 端口
- 业务 B:81 端口
- web RS2:172.17.0.3
- 业务 A:80 端口
- 业务 B:81 端口
RS1 上的 nginx 配置 server 块:
server { |
RS2 上的 nginx 配置 server 块:
server { |
LB1 和 LB2 的 nginx 上配置负载均衡:
upstream business-a-pool { |
LB 上的 keepalived 配置沿用上面双实例的配置。
LB1 和 LB2 的 nginx 的 server 块一致,配置如下:
server { |
依次访问两个业务,实现了多实例的负载均衡与高可用:
$ curl 172.16.1.100 |
解决服务监听网卡上不存在 IP 地址的问题
若在 nginx 配置中 server 块的 listen 配置一个本机没有的 ip 地址,则会报错
解决方法:在/etc/sysctl.conf添加配置net.ipv4.ip_nonlocal_bind = 1或通过命令sysctl -w net.ipv4.ip_nonlocal_bind=1
然后sysctl -p使配置生效。
解决高可用服务只针对物理服务器的问题
若出现机器未宕机且 keepalived 正常工作,然而是服务挂了,keepalived 则无法进行切换。有两种方法解决当服务挂掉的时候也能实现 keepalived 的 IP 漂移切换。
- 写守护进程脚本处理。当本地 nginx 业务出现问题,就强制停掉 keepalived 以实现 IP 漂移。
!/bin/bash
while true
do
if [ `netstat -lntup | grep nginx | wc -l` ne 1 ]; then
systemctl stop keepalived
fi
sleep 5
done - 使用监测脚本,然后配置在 keepalived 的配置文件中。脚本与上面类似,但是去掉
sleep 5,然后在配置文件中添加:并在 vrrp 实例中添加vrrp_script chk_nginx_proxy {
script "脚本路径"
interval 2 //当nginx挂掉时,keepalived在2秒内就会按照脚本停止
}track_script {
chk_nginx_proxy
}
解决多组 keepalived 服务器在一个局域网的冲突问题
若同一个局域网内存在多组 keepalived 服务器对,就会造成 IP 多播地址冲突问题,导致接管错乱,不同组 keepalived 都会默认使用224.0.0.18作为多播地址。
解决方法:每个 keepalived 对指定唯一多播地址。
global_defs { |
配置指定文件接受 Keepalived 日志
keepalived 默认日志输出到/var/log/messages,所以最好单独记录该日志。
修改/etc/sysconfig/keepalived,
KEEPALIVED_OPTIONS="-D -d -S 0" |
选项含义:
# --vrrp -P 只与vrrp子系统运行 |
然后在/etc/rsyslog.conf中添加 keepalived 配置
local0.* /var/log/keepalived.log |
并在*.info;mail.none;authpriv.none;cron.none后添加local0.none
*.info;mail.none;authpriv.none;cron.none;local0.none /var/log/messages |
重启 rsyslog 服务 systemctl restart rsyslog.service
开发监测 Keepalived 裂脑脚本
在备服务器上执行脚本,若能 ping 通主节点且备节点有 VIP,就报警。
!/bin/bash |
参考文档
LVS 中文官方文档 > 骏马金龙 LVS 系列文章 > 负载均衡的原理
高性能网站构建实战
Linux 之虚拟服务器 LVS 搭建