学习 Namespace 的笔记与 C 语言 Demo 参考书目:《Docker 容器与容器云》
简介 Linux 提供了 6 种 Namespace 隔离。
namespace
系统调用参数
隔离内容
UTS
CLONE_NEWUTS
主机名与域名
IPC
CLONE_NEWIPC
信号量、消息队列、共享内存
PID
CLONE_NEWPID
进程编号
Network
CLONE_NEWNET
网络设备、网络栈、端口等
Mount
CLONE_NEWNS
挂载点
User
CLONE_NEWUSER
用户与用户组
namespace 有以下 API:clone()、setns()、unshare()
clone()是 Linux 系统调用 fork()的一种更通用的方式
int clone(int (_child_func)(void _), void *child_stack, int flags, void *arg); child*func 传入子进程运行的程序主函数 child_stack 传入子程序使用的栈空间 flags 表示使用哪些 CLONE*\*标志位 args 传入用户参数
从 3.8 版本开始,可通过/proc/[pid]/ns 目录查看指向不同 namespace 号的文件,[]中的就是 namespace 号。
ll /proc/\$\$/ns lrwxrwxrwx. 1 root root 0 1 月 9 05:31 ipc -> ipc:[4026531839] lrwxrwxrwx. 1 root root 0 1 月 9 05:31 mnt -> mnt:[4026531840] lrwxrwxrwx. 1 root root 0 1 月 9 05:31 net -> net:[4026531956] lrwxrwxrwx. 1 root root 0 1 月 9 05:31 pid -> pid:[4026531836] lrwxrwxrwx. 1 root root 0 1 月 9 05:31 user -> user:[4026531837] lrwxrwxrwx. 1 root root 0 1 月 9 05:31 uts -> uts:[4026531838]
设置链接的作用:一旦 link 文件被打开,只要打开的文件描述符存在,则即使该 namespace 下的所有进程都结束,这个 namespace 仍会继续存在,后续的进程仍能加入进来。
通过 setns()加入一个已存在的 namespace
int setns (int fd, int nstype) ;fd 为要加入 namespace 的文件描述符 nstype 让调用者检查 fd 指向的 namespace 类型是否符合实际要求。若为 0 表示不检查
通过 unshare()在原先进程上进行 namespace 隔离,而不用启动新的进程。Docker 暂时还没有使用此调用。
fork()系统调用,fork 函数不属于 namespace 的 API,属于 Linux 系统自带的调用。能创建新的进程,并分配资源。fork()调用一次却能返回两次,父进程和子进程各返回一次。可能有三种返回值:
在父进程中,返回新创建的子进程的进程 ID
在子进程中,返回 0
若出现错误,返回一个负值
一个实例代码:
#include <unistd.h> #include <stdio.h> int main () { pid_t fpid; int count = 0 ; fpid = fork(); if (fpid < 0 ) printf ("error" ); else if (fpid == 0 ) printf ("child process id: %d\n" , getpid()); else printf ("parent process id: %d\n" , getpid()); return 0 ; }
编译后输出:
parent process id: 33008 child process id: 33009
在使用 fork()函数后,父进程有义务监视子进程的运行状态,并在子进程退出后自己才能正常退出,否则子进程就会孤儿进程。对于孤儿进程,会直接由上级的父进程接管。
以下是 6 种隔离的具体实现,以下为学习顺序
UTS 简单实现 UTS 隔离,实现代码uts.c
#define _GNU_SOURCE #include <sys/types.h> #include <sys/wait.h> #include <stdio.h> #include <sched.h> #include <signal.h> #include <unistd.h> #define STACK_SIZE (1024*1024) static char child_stack[STACK_SIZE];char * const child_args[] = {"/bin/bash" , NULL };int child_main (void * args) { printf ("在子进程中!\n" ); sethostname("newnamespace" , 12 ); execv(child_args[0 ], child_args); return 1 ; } int main () { printf ("程序开始\n" ); int child_pid = clone(child_main, child_stack + STACK_SIZE, CLONE_NEWUTS | SIGCHLD, NULL ); waitpid(child_pid, NULL , 0 ); printf ("已退出\n" ); return 0 ; }
编译运行,实现了域名隔离
[root@s1 uts]# gcc -Wall uts.c -o uts [root@s1 uts]# ./uts 程序开始 在子进程中! [root@newnamespace uts]# exit exit 已退出 [root@s1 uts]#
IPC 简单实现 IPC 隔离,代码与 uts.c 基本一致,只需要添加一个标识位CLONE_NEWIPC
int child_pid = clone(child_main, child_stack + STACK_SIZE, CLONE_NEWIPC | CLONE_NEWUTS | SIGCHLD, NULL );
先创建一个消息队列
[root@s1 ipc]# ipcmk -Q Message queue id: 0 [root@s1 ipc]# ipcs -q ------ Message Queues -------- key msqid owner perms used-bytes messages 0xf1646a41 0 root 644 0 0
编译后运行 ipc
[root@s1 ipc]# gcc -Wall ipc.c -o ipc [root@s1 ipc]# ./ipc 程序开始 在子进程中! [root@newnamespace ipc]# ipcs -q ------ Message Queues -------- key msqid owner perms used-bytes messages
已实现了 IPC 隔离,在子进程中查看不到原先创建的消息队列
PID 每个 PID namespace 都有自己的计数器,内核为所有 PID namespace 维护一个树状结构,最顶层是系统初始化时创建的,称为 root namespace,新的 Namespace 称为 child namespace。
同样代码仍然使用ipc.c 的,只要添加一个标志位CLONE_NEWPID,保存为pid.c
int child_pid = clone(child_main, child_stack + STACK_SIZE, CLONE_NEWPID | CLONE_NEWIPC | CLONE_NEWUTS | SIGCHLD, NULL );
首先查看当前的 shell 的 PID,再运行 pid,查看 shell 的 PID
[root@s1 pid]# echo $$ 35580 [root@s1 pid]# ./pid 程序开始 在子进程中! [root@newnamespace pid]# echo $$ 1
init 进程的 PID 为 1,作为所有进程的父进程,维护一张进程表,检查进程状态,一旦有子进程因父进程的错误变为孤儿进程,init 会收养该子进程,并回收资源,结束进程。
内核为 PID namespace 中的 init 进程赋予了信号屏蔽 的特权,若 init 中没有编写处理某个信号的代码,则与 init 同一个 PID namespace 的进程发送给 init 的该信号就会被屏蔽。主要用于防止 init 进程被误杀。
父节点向子节点发送的除SIGKILL或SIGSTOP信号外的其他信号也会被子节点屏蔽。而对于SIGKILL和SIGSTOP信号,子节点会强制执行,因此,父节点有权终止子节点的进程。
当子节点的 init 进程被销毁,即使/proc/[pid]/ns/pid处于挂载或打开状态,导致 namespace 保存下来,但该 namespace 也无法通过setns()或fork()创建进程。
当一个容器中存在多个进程时,容器内的 init 进程可对信号捕获,对子进程做信息保存、资源回收等处理。
在新的 PID namespace 中用ps查看,仍然会看到所有进程。因为与 PID 相关的/proc文件系统profs没有挂载到一个与原/proc不同的位置
[root@newnamespace pid]# ps -a PID TTY TIME CMD 36025 pts/1 00:00:00 pid 36026 pts/1 00:00:00 bash 36060 pts/1 00:00:00 ps
挂载文件系统 proc 到/proc
[root@newnamespace pid]# mount -t proc proc /proc [root@newnamespace pid]# ps a PID TTY STAT TIME COMMAND 1 pts/1 S 0:00 /bin/bash 38 pts/1 R+ 0:00 ps a
但此时并没有进行 mount namespace 的隔离,所以该操作实际上影响了 root namespace 的文件系统。因此退出后,仍要重新挂载 proc:mount -t proc proc /proc
调用unshare()和setns()创建新的 PID namespace 时,该调用程序并不进入,而是之后创建的子进程才会进入 namespace,成为 init。因为调用getpid()函数得到的 PID 是根据调用者所在的 PID namespace 决定返回哪个 PID,进入新的 PID namespace 会导致 PID 变动,造成进程错误。
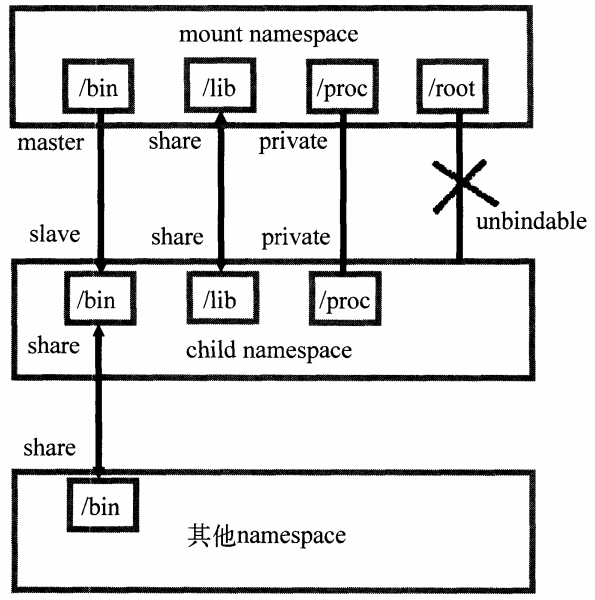
Mount 通过隔离文件系统挂载点对隔离文件系统提供支持,是第一个支持的 Linux namespace。
进程创建 mount namespace 时,会把当前的文件结构复制给新的 namespace,并且子节点中的挂载只影响自身,不影响外部。但也会有例外,因此,2006 年引入的挂载传播 解决了该问题,定义了挂载对象(mount object)间的关系:
共享挂载(share relationship):若两个挂载对象具有共享关系,则一个挂载对象中的挂载事件会传播到另一个挂载对象,反之亦然。
从属关系(slave relationship):若两个挂载对象形成从属关系,则一个挂载对象中的挂载事件会传播到另一个挂载对象,反之不行。从属对象是事件的接受者。
有可能出现的挂载状态:
共享挂载(share):传播事件的挂载对象
从属挂载(slave):接收传播事件的挂载对象
共享/从属挂载(shared and slave):既传播又接收事件的挂载对象
私有挂载(private):既不传播也不接收事件的挂载对象
不可绑定挂载(unbindable):类似私有挂载,但不允许执行绑定挂载,即这块文件对象不可被复制
mount提供以上的各种挂载方式:
--make-shared mark a subtree as shared --make-slave mark a subtree as slave --make-private mark a subtree as private --make-unbindable mark a subtree as unbindable --make-rshared recursively marka whole subtree as shared --make-rslave recursively marka whole subtree as slave --make-rprivate recursively marka whole subtree as private --make-runbindable recursively marka whole subtree as unbindable
代码仍然只需要添加标志位CLONE_NEWNS
#define _GNU_SOURCE #include <sys/types.h> #include <sys/wait.h> #include <stdio.h> #include <sched.h> #include <signal.h> #include <unistd.h> #define STACK_SIZE (1024*1024) static char child_stack[STACK_SIZE];char * const child_args[] = {"/bin/bash" , NULL };int child_main (void * args) { printf ("在子进程中!\n" ); sethostname("newnamespace" , 12 ); execv(child_args[0 ], child_args); return 1 ; } int main () { printf ("程序开始\n" ); int child_pid = clone(child_main, child_stack + STACK_SIZE, CLONE_NEWNS | CLONE_NEWPID | CLONE_NEWIPC | CLONE_NEWUTS | SIGCHLD, NULL ); waitpid(child_pid, NULL , 0 ); printf ("已退出\n" ); return 0 ; }
编译后运行,挂载 CDROM
[root@newnamespace mount]# mount /dev/cdrom /mnt mount: /dev/sr0 is write-protected, mounting read-only [root@newnamespace mount]# df Filesystem 1K-blocks Used Available Use% Mounted on /dev/mapper/centos-root 17811456 1836940 15974516 11% / ...... /dev/sda1 1038336 129608 908728 13% /boot /dev/sr0 4414592 4414592 0 100% /mnt
Network 网络隔离包括:网络设备、IPv4 和 IPv6 协议栈、IP 路由表、防火墙、/proc/net、/sys/class/net、套接字等。
通过创建 veth pair(虚拟网络设备对)实现容器内外的通信。当创建的 network namespace 被释放时,这个 namespace 中的物理网卡会返回到 root namespace,而不是创建 namespace 的父进程。
在建立好 veth pair 前,新旧 namespace 间通过管道(pipe)通信。以 docker 为例,docker daemon 在宿主进程上创建 veth pair,把一端绑定在 docker0 网桥上,另一端接入新建的 network namespace,在 veth pair 建立完成前,docker daemon 和 init 通过管道通信,直到 init 接收到 docker daemon 发送的 veth 设备信息,然后关闭管道,并启动 eth0。
代码仅需要在 mount.c 上添加标志位CLONE_NEWNET,保存为network.c
int child_pid = clone(child_main, child_stack + STACK_SIZE, CLONE_NEWNET | CLONE_NEWNS | CLONE_NEWPID | CLONE_NEWIPC | CLONE_NEWUTS | SIGCHLD, NULL );
编译运行后,查看网络设备,只有一个环回口
[root@s1 network]# ./network 程序开始 在子进程中! [root@newnamespace network]# ifconfig [root@newnamespace network]# ip addr 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN qlen 1 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
User user namespace 主要隔离安全相关的标识符和属性,包括用户(组)ID、root 目录、密钥和特殊权限。user namespace 也类似 PID namespace,是树状结构。
为了能查看用户权限,需要在代码中添加内容。需要导入sys/capability.h,该包需要安装libcap-dev(debian)或libcap-devel(redhat)。
在child_main函数中添加
int child_main (void * args) { cap_t caps; printf ("在子进程中!\n" ); sethostname("newnamespace" , 12 ); printf ("eUID=%ld, eGID=%ld\n" , (long )geteuid(), (long )getegid()); caps = cap_get_proc(); printf ("capabilities: %s\n" , cap_to_text(caps, NULL )); execv(child_args[0 ], child_args); return 1 ; }
并在 main 函数添加标志位CLONE_NEWUSER,并且需要删除以前的CLONE标识符,否则可能无法正常显示。
int child_pid = clone(child_main, child_stack + STACK_SIZE, CLONE_NEWUSER | SIGCHLD, NULL );
因为添加了 capability 头文件,在编译时需要添加选项-lcap。gcc -Wall -lcap userns.c -o userns
root:user > ./userns 程序开始 在子进程中! eUID=65534, eGID=65534 capabilities: = cap_chown,cap_dac_override,...... nobody:user >
子节点的 UID 和 GID 都变为了 65534(默认的),并且用户名变为 nobody。capabilities 为子节点中该用户的权限,已经有所有权限了。65534 表示尚未与外部的 namespace 的用户(组)映射。
进行用户绑定,通过在/proc/[pid]/uid_map和/proc/[pid]/gid_map写入对应绑定信息即可。
ID-inside-ns ID-outside-ns length
注:
这两个文件仅允许拥有该 user namespace 中 CAP_SETUID 的进程写入一次,不允许修改 写入的进程必须是 user namespace 的父 namespace 或子 namespace 第一个字段ID-inside-ns表示新建的 user namespace 中对应的 UID/GID,第二个字段ID-outside-ns表示外部映射的 UID/GID,length表示映射范围,通常就填 1,表示只映射一个。
创建函数设置 UID 和 GID
void set_uid_map (pid_t pid, int inside_id, int outside_id, int length) { char path[256 ]; sprintf (path, "/proc/%d/uid_map" , getpid()); FILE* uid_map = fopen(path, "w" ); fprintf (uid_map, "%d %d %d" , inside_id, outside_id, length); fclose(uid_map); } void set_gid_map (pid_t pid, int inside_id, int outside_id, int length) { char path[256 ]; sprintf (path, "/proc/%d/gid_map" , getpid()); FILE* gid_map = fopen(path, "w" ); fprintf (gid_map, "%d %d %d" , inside_id, outside_id, length); fclose(gid_map); }
然后在 child_main 函数中添加对这两个函数的调用
int child_main (void * args) { cap_t caps; printf ("在子进程中!\n" ); set_uid_map(getpid(), 0 , 1000 , 1 ); set_gid_map(getpid(), 0 , 1000 , 1 ); printf ("eUID=%ld, eGID=%ld\n" , (long )geteuid(), (long )getegid()); caps = cap_get_proc(); printf ("capabilities: %s\n" , cap_to_text(caps, NULL )); execv(child_args[0 ], child_args); return 1 ; }
userns.c完整文件:
#define _GNU_SOURCE #include <sys/types.h> #include <sys/wait.h> #include <stdio.h> #include <sched.h> #include <signal.h> #include <unistd.h> #include <sys/capability.h> #define STACK_SIZE (1024*1024) static char child_stack[STACK_SIZE];char * const child_args[] = {"/bin/bash" , NULL };void set_uid_map (pid_t pid, int inside_id, int outside_id, int length) { char path[256 ]; sprintf (path, "/proc/%d/uid_map" , getpid()); FILE* uid_map = fopen(path, "w" ); fprintf (uid_map, "%d %d %d" , inside_id, outside_id, length); fclose(uid_map); } void set_gid_map (pid_t pid, int inside_id, int outside_id, int length) { char path[256 ]; sprintf (path, "/proc/%d/gid_map" , getpid()); FILE* gid_map = fopen(path, "w" ); fprintf (gid_map, "%d %d %d" , inside_id, outside_id, length); fclose(gid_map); } int child_main (void * args) { cap_t caps; printf ("在子进程中!\n" ); set_uid_map(getpid(), 0 , 1000 , 1 ); set_gid_map(getpid(), 0 , 995 , 1 ); printf ("eUID=%ld, eGID=%ld\n" , (long )geteuid(), (long )getegid()); caps = cap_get_proc(); printf ("capabilities: %s\n" , cap_to_text(caps, NULL )); execv(child_args[0 ], child_args); return 1 ; } int main () { printf ("程序开始\n" ); int child_pid = clone(child_main, child_stack + STACK_SIZE, CLONE_NEWUSER | SIGCHLD, NULL ); waitpid(child_pid, NULL , 0 ); printf ("已退出\n" ); return 0 ; }
重新编译执行,结果如下
gutianyi:user > ./userns 程序开始 在子进程中! eUID=0, eGID=0 capabilities: = cap_chown...... root:user >
注:执行的用户必须是set_uid_map和set_gid_map中 outside_id 对应的用户。
Linux 内核将原来与超级用户相关的高级权限划分为不同的单元,称为 Capability。管理员可独立对特定的 Capability 进行使用或禁用。在 Docker 中同时使用了 user namespace 和 Capability,加强了容器安全性。