





分布式文件系统
Distributed File System(DFS)分布式文件系统是开放软件基金会(OSF)的分布式计算环境(DCE)中的文件系统部分,指文件系统管理的物理存储资源不一定直接连接在本地节点上,具有以下特性:
- 只读共享:任何客户端只能访问文件,不能修改。
- 受控写操作:允许多个用户打开同一个文件,但只有一个用户能进行写操作,并且该用户的修改不能立刻在其他用户上体现。
- 并发写操作:允许多个用户同时读写一个文件,需要操作系统进行大量监控工作防止文件重写,并保证用户看到最新消息。
传统的 DFS,如 NFS,所有的数据和元数据存放在一起,通过单一的存储服务器提供服务,这种模式称为In-band Mode,随着客户端数量增加,服务器成为整个文件系统的瓶颈。
新型的 DFS 利用存储区域网络(SAN),将应用服务器直接与存储设备连接,提升了传输能力,应用服务器直接访问 SAN 中的数据,只有关于信息的元数据才经过元数据服务器处理,减少了数据传输的中间环节,减轻了元数据服务器的负载。这种模式称为Out-band Mode。
区分两种模式的依据:元数据操作的控制信息是否与文件数据一起通过服务器转发。In-band Mode 需要服务器转发,Out-band Mode 可直接访问。
MFS 概述
MooseFS 是一个具备容错功能的高可用分布式网络文件系统,MFS 将数据分散在多台服务器上,确保一份数据有多份备份,且备份分布在不同服务器上,而用户看到的只是一个资源,即对用户透明。MFS 就类似一个 unix 的文件系统,包含层级结构、文件属性等。
- 分层目录树结构
- 存储支持 POSIX 标准的文件属性
- 支持特殊文件,如块设备、字符设备、管道、套接字、链接文件
- 支持基于 IP 地址和密码的方式访问文件系统
MFS 特性:
- 高可靠性:一份数据多份副本
- 高可扩展性:轻松实现横向或纵向扩展
- 高可容错性:可实现回收站机制
- 高数据一致性:即使文件被写入或访问时,仍可以进行一致性快照
MFS 应用场景:
- 大规模高并发的线上数据存储及访问
- 大规模数据处理,如日志分析。
- 尽量在文件系统服务器前架设缓存服务器,而不是一味地扩容
MFS 组成:
- 管理服务器(managing servers):也称 master servers,管理整个文件系统的主机,存储每个文件的元数据(大小信息、属性、文件路径)
- 数据存储服务器(data servers):也称 chunk servers,存储文件并进行同步的服务器,如果确定的话,文件要做多于一份的备份。此服务器是真正的数据载体,最好组 raid5 或 raid0 或 raid10。实际环境中应该至少有三台以上。
- 元数据备份服务器(metadata backup servers):也称 metalogger server,存储元数据修改日志并周期下载主元数据文件
- 客户端:使用
mfsmount进程与管理服务器或数据存储服务器通信以获取与修改元数据信息的主机
MFS 读过程
- 客户端向元数据服务器(master)发出读请求。
- 元数据服务器把所需数据的存放位置(chunk server IP 和 chunk 编号)告知客户端
- 客户端向已知的 chunk server 发送请求
- chunk server 向客户端发送数据。
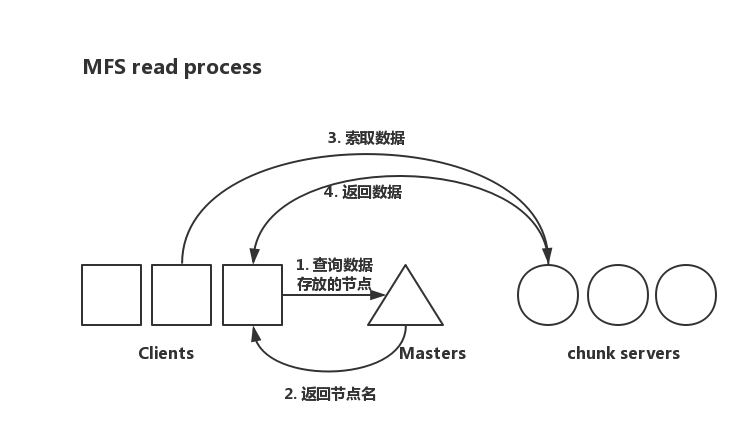
数据传输并不经过元数据服务器,减轻了元数据服务器的压力,也增大了整个系统的吞吐能力。
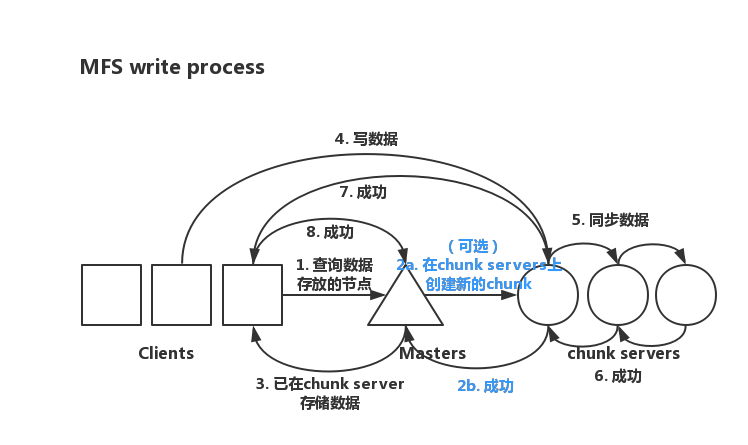
MFS 写过程
客户端向元数据服务器发送写请求
元数据服务器与 chunk server 交互(只要当所需 chunks 存在才交互)
a. 元数据服务器在某些服务器上创建 chunks
b. chunk server 告知元数据服务器 chunks 创建成功
元数据服务器告知客户端可写的 chunk server 上的指定 chunks
客户端向指定 chunk server 写数据
chunk server 之间进行同步
chunk server 互相通知同步成功
chunk server 告知客户端写入成功
客户端告知元数据服务器写入成功
MFS 简单部署
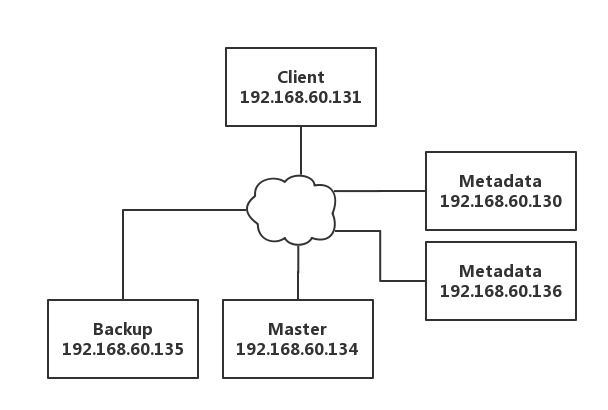
实验环境:
Master:192.168.60.134
MFS VIP:192.168.60.200
Backup:192.168.60.135
Chunk1:192.168.60.136
Chunk2:192.168.60.130
Client:192.168.60.131
先要配置官方源,官网配置,版本 3.0
对 Master:yum install moosefs-master moosefs-cgi moosefs-cgiserv moosefs-cli
对 chunkserver:yum install moosefs-chunkserver
对 metalogger:yum install moosefs-metalogger
对 Client:yum install moosefs-client
启动 master
Master 的配置文件目录/etc/mfs/
mfsexports.cfg:被挂载目录及权限控制文件mfsmaster.cfg:master 主配置文件mfstopology.cfg:
mfsmaster.cfg
WORKING_USER = mfs # 运行master的用户 |
mfsexports.cfg
文件格式
客户端IP地址(或范围) 挂载点 参数 |
其中挂载点路径有两个注意:
/表示以 MFS 根为根目录.表示以 MFSMETA 文件系统为根目录
参数可设置以下访问权限,逗号分隔多个参数:
- ro:只读
- rw:读写
- alldirs:允许挂载任何指定的子目录
- maproot:映射为 root
- password:指定客户端密码
启动操作
先在 master 上配置 VIP。ifconfig ens32:0 192.168.60.200/24 up。
在 master 上使用命令mfsmaster start即可启动主服务器。会开启三个端口
master <-> metaloggers module: listen on *:9419 |
其中 9419 用于监听 metalogger,9420 监听 chunkserver,9421 监听 master
mfsmaster |
可以使用命令mfscgiserv start启动 MFS 的图形化 web 监控,通过 9425 端口访问,该图形化 web 是用 python 写的。
启动 metalogger
配置文件/etc/mfs/mfsmetalogger.cfg
MASTER_HOST = mfsmaster # 可配置master的主机名(需要在/etc/hosts中配置)、IP地址、域名等指定master |
启动 metalogger,mfsmetalogger start,查看端口可看到与 master 建立了长连接
ESTAB 0 0 192.168.60.135:40476 192.168.60.200:9419 users:(("mfsmetalogger",pid=7735,fd=8)) |
mfsmetalogger命令与mfsmaster类似。
启动 chunkserver
准备磁盘,分区、制作文件系统并挂载。
mount /dev/sdb1 /var/mfsdata |
chunkserver 挂载点配置文件/etc/mfs/mfshdd.cfg,只要将挂载点写入该文件即可。
echo "/var/mfsdata" >> /etc/mfs/mfshdd.cfg |
参数配置文件/etc/mfs/mfschunkserver.cfg
MASTER_HOST = mfsmaster # 同metalogger,要与hosts中一致 |
命令mfschunkserver start启动 chunkserver。
但通过 web 查看状态,发现已经使用了 260M 左右。

因为 master 向 data 服务器申请空间是按最少 256M 申请的,低于 256M 则不会再申请空间,因此用于 MFS 的磁盘空间一定要大于 256M,并且空闲的空间一定要大于 1G 才能参与分配,即用于 MFS 磁盘的空间大小至少大于 1G,应该从几个 G 开始。
启动 client
MFS 客户端的挂载依赖于 fuse 工具,需要先安装。默认系统已安装。但需要安装内核模块modprobe fuse。客户端上也要配置hosts文件添加 mfsmaster。
创建 mfs 组与 mfs 用户,创建挂载目录
groupadd mfs |
使用mfsmount挂载 mfs。mfsmount /mnt/mfsdata -H mfsmaster
挂载完成后,查看df可发现挂载成功。
客户端的/bin/中有许多 mfs 的工具,但都指向mfstools
在挂载目录中创建文件
# touch 1.conf |
在客户端的/mnt/mfsdata/中有以下目录
# ls |
创建备份mfssetgoal -r 3 conf,备份三份 conf 目录。
# mfssetgoal -r 3 conf |
查看文件备份情况
# mfsgetgoal conf |
MFS 数据存放在 chunk 中,类似 block,数据是会分为多个 chunk 的,每个 chunk 的大小为 64M,若一个文件大于 64M,则会分为多个 chunk。
# dd if=/dev/zero of=./aaa bs=1M count=63 # 63M的文件在一个chunk中 |
查看文件删除后会在回收站里的时间
# mfsgettrashtime conf/1.conf |
设置文件删除后在回收站里的时间
# mfssettrashtime -r 864000 conf/ # -r递归设置 |
挂载 mfs 回收站
# mfsmount -H mfsmaster -m /mnt/mfs-trash |
master 宕机切换
在 master 上/var/lib/mfs/中存放修改记录changelog.X.mfs和元数据记录metadata.mfs.back
在 backup 的/var/lib/mfs/中也存放着修改记录changelog_ml.X.mfs和元数据记录metadata_ml.mfs.back和metadata.mfs
若要在 backup 上恢复数据并身份转为 master,可以通过命令mfsmaster -a直接恢复。
注:
mfsmetarestore命令在 1.7 版本已被废除。
MFS 集群内各角色的启动与停止
规范的启动顺序:
- 启动 Masters
- 启动所有 chunk servers
- 启动 metalogger
- 挂载客户端
规范的停止顺序:
- 客户端卸载挂载
- 停止所有 chunk servers
- 停止 metalogger
- 停止 master
MFS 高可用
有几个解决方法:
- 部署多个日志备份服务器(metalogger)
- 使用 heartbeat 或 keepalived+DRBD 实现 master 高可用
- 使用 keepalived+inotify 实现 master 高可用(不推荐)
keepalived+DRBD 实现高可用
实验环境:
- Master:192.168.60.134
- Backup:192.168.60.135
- Chunk1:192.168.60.136
- Chunk2:192.168.60.130
- Client:192.168.60.131
在 Master 和 Backup 上设置 DRBD 分区,sdc 大小 2G,sdc1 有 400M 做元数据存储,剩余 sdc2 做数据存储。
设备 Boot Start End Blocks Id System |
在 Master 和 Backup 上都修改 DRBD 配置,创建mfs.res
resource mfsdata { |
创建 DRBD 操作
drbdadm create-md all |
配置 keepalived,在两台主机上配置
global_defs { # 保持默认即可 |